
이번 포스트는 포텐데이 412에서 1등을 했던 테블리의 핵심 기능을 개발하며 겪었던 문제 및 트러블 슈팅을 다뤄보려고 한다.
필요한 데이터 수집하기(티스토리)
테블리는 이름 그대로 '테크 블로그 리포트'라는 서비스다.
구체적으로는 블로그에 글을 발행하는 개발자들을 주 타겟으로 2024년 자신의 블로그에 대한 분석 및 연말 결산을 해주는 서비스이다.
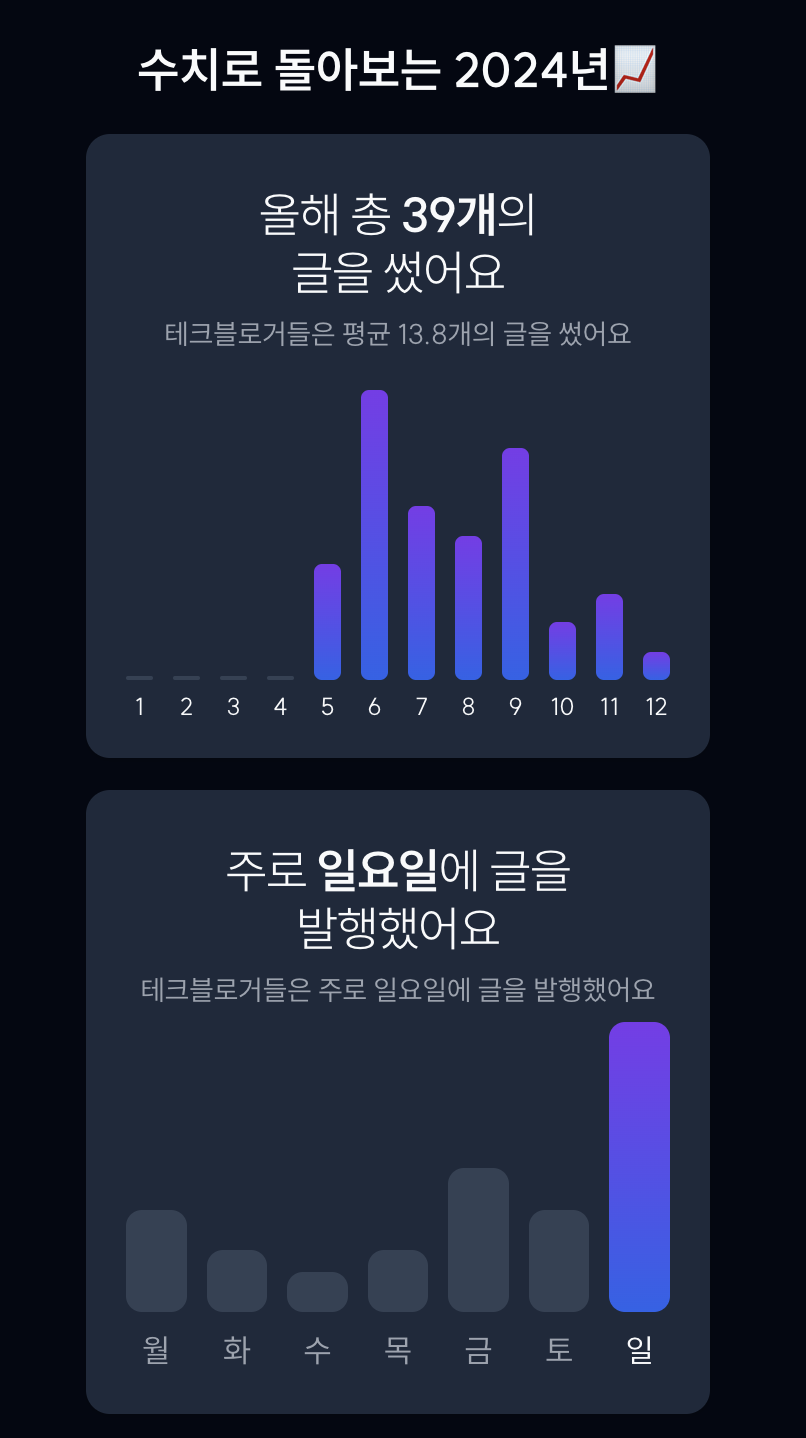
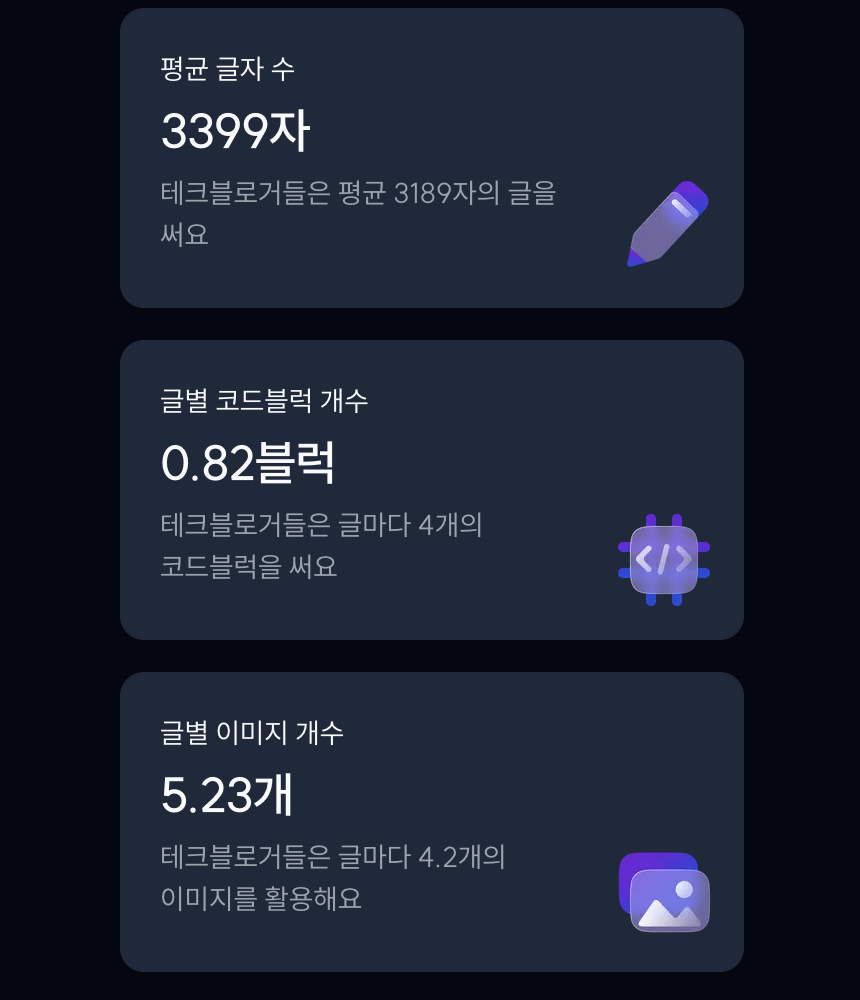
사용자로부터 블로그의 링크를 입력으로 받으면, 사용자가 '2024년 총 몇개의 글을 썼는지', '주로 어떤 요일에 글을 썼는지', '글 별 평균 글자수', '글별 코드블럭 수', '글별 이미지 개수' 등을 보여주기 위해 해당 블로그로부터 필요 데이터를 빠르게 수집해서 통계를 보여줘야 했다.
이 때, 테블리에서 지원했던 플랫폼은 개발자들이 기술 블로그로 많이 사용하는 '티스토리'와 '벨로그'였는데 해당 플랫폼들에서 데이터를 수집하는 과정과 트러블 슈팅 과정에 대해 정리해보려고 한다.
먼저 이번 포스팅에서는 글또 기준, 기술 블로그로 가장 많이 사용하고 있던 티스토리에 대한 트러블 슈팅 과정을 다뤄봤다.
1. 너무 많은 (커스텀) 스킨
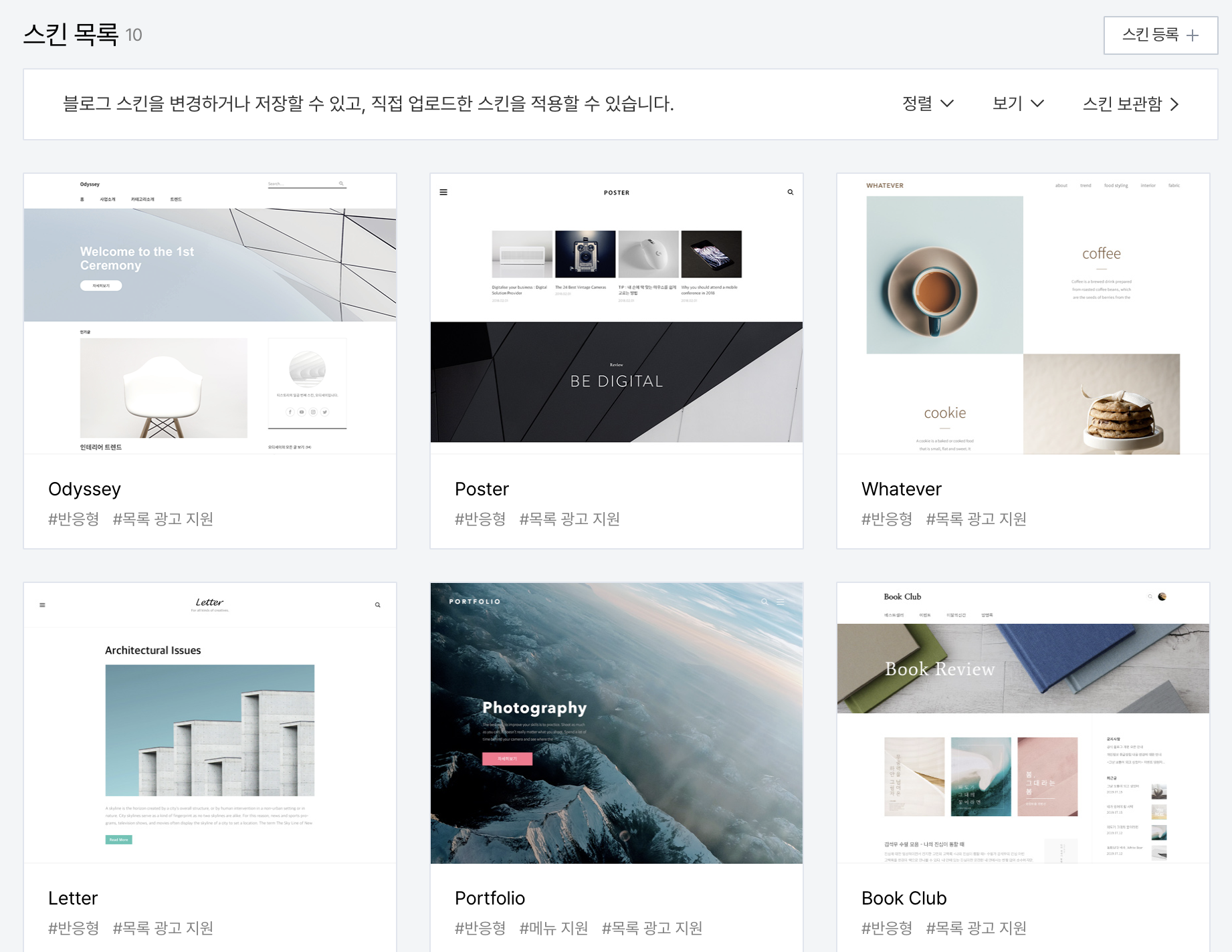
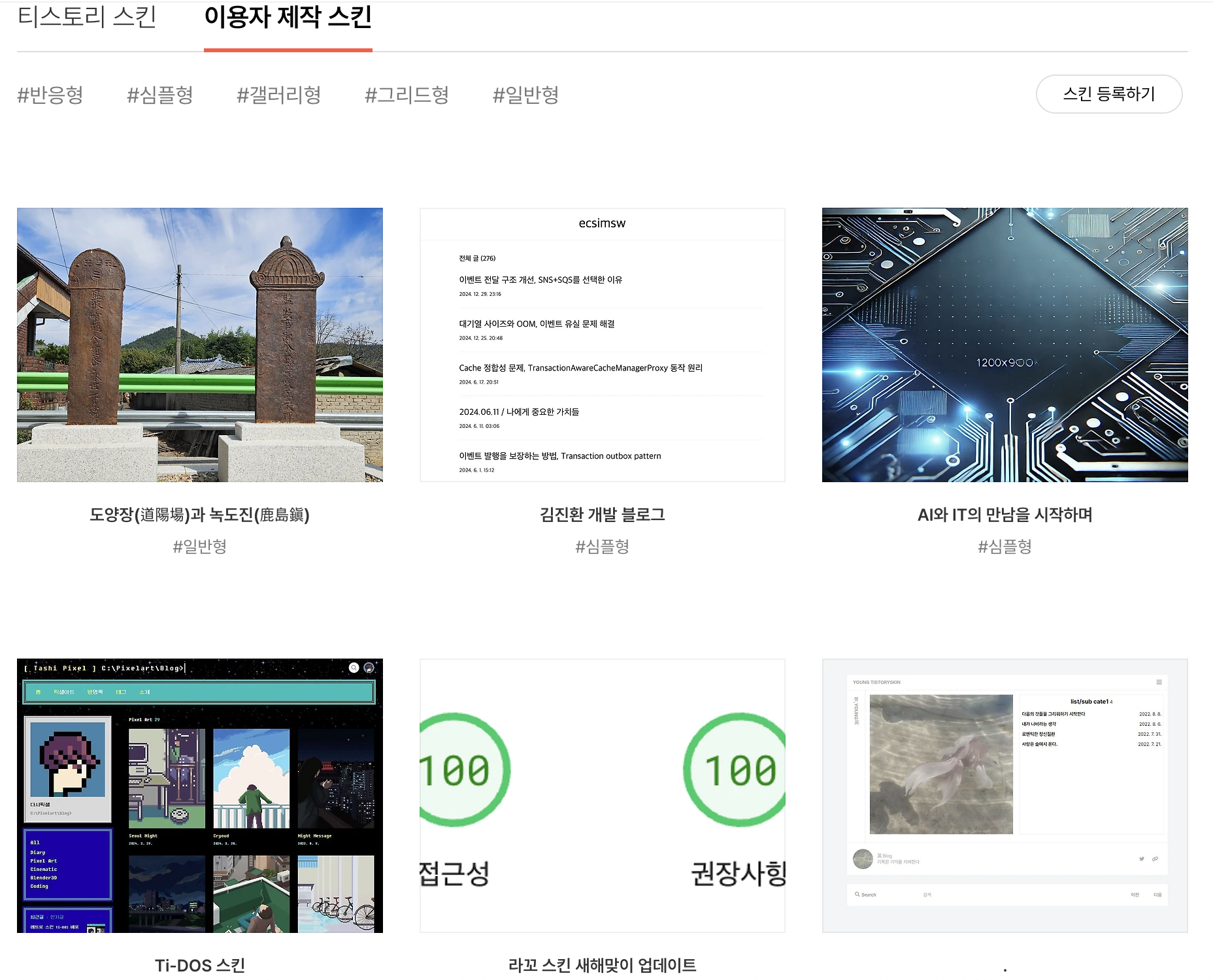
우선 티스토리의 경우, 벨로그와 달리 사용자가 여러 스킨을 선택할 수 있다.
기본적으로 티스토리에서 제공하는 스킨만 10가지이며, 이외에도 사용자가 직접 만든 커스텀 스킨(?)이 존재한다. (대표적으로는 heLLO 스킨)
문제는 기본 제공되는 티스토리 스킨이 개인적으로 HTML을 편집할 수 있다는 점이었다. 이로 인해, 블로그마다 HTML과 CSS 구조가 달라졌고, 데이터를 가져오는 방식을 각 스킨에 맞춰 개별적으로 처리해야 했다.
초기에는 팀원들의 블로그를 대상으로 처리 코드를 작성했고, 이후 티스토리에서 제공하는 스킨들, 유명 커스텀 스킨들로 처리 로직을 확장해나갔다.
1. POTENTIAL_CLASSES
POTENTIAL_CLASSES = [
'post', 'list', 'list-list', 'article-type-common', 'post-item', 'article_content', 'content-list', 'index-item', re.compile(r'\blist\b.*content__index'), 'index-template', 'list content__index', 'list_content_text',
'item_category', 'link_thumb', 'list_content', 'index-article-item',
'one_article', 'fc-list-item', 'index-item-wrap', 'index-list-content',
'posts-index-item w-full h-auto border border-solid cursor-pointer relative'
]다음과 같이 기본적으로 티스토리에서 제공하는 스킨과 유명 커스텀 스킨인 heLLO 등 최대한 모든 블로그 스킨에 대응하기 위해 다양한 스킨에서 자주 사용되는 클래스 이름을 POTENTIAL_CLASSES로 정의했다.
2. 각 스킨별 처리코드
@staticmethod
def detect_post_elements(soup: BeautifulSoup):
"""
글 정보를 포함할 가능성이 높은 후보를 탐색하여 반환.
"""
# 1. 우선적으로 ul > li > span.title 구조를 가진 요소 탐색
articles = soup.select('ul li:has(span.title)')
uses_post_class = False
# 2. 추가 탐색: 특정 클래스 기반으로 탐색
for class_name in POTENTIAL_CLASSES:
if class_name == "post":
# post 클래스 처리
post_elements = soup.select(".post")
if post_elements:
uses_post_class = True
articles.extend(post_elements)
break # 탐색 중단 (post 클래스가 우선순위 높음)
elif class_name in ["list", "list-list"]:
# list 및 list-list 클래스에서 li와 중첩된 div.item 탐색
articles.extend(
soup.select(f".{class_name} ul li, .{class_name} ul div.item")
)
elif isinstance(class_name, str):
# 단일 클래스 탐색
articles.extend(soup.select(f".{class_name}"))
elif isinstance(class_name, re.Pattern):
# 정규식 기반 클래스 탐색
articles.extend(soup.find_all(class_=class_name))(위 코드는 예시코드로 실제 코드는 좀 더 세부적인 처리 로직이 들어가있다.)
detect_post_elements 메서드에서 POTENTIAL_CLASSES에 정의된 클래스를 순차적으로 탐색하고, HTML 구조가 다를 수 있는 커스텀 스킨을 유연하게 처리하기 위해, 클래스 기반 탐색과 정규식 탐색을 포함시켜 최대한 모든 스킨에 대해 공통된 부분을 찾고, 예외는 별도로 대응하고자 했다.
해당 코드에는 포함돼있지 않지만, 서비스를 운영하며 추가적으로 발생한 버그들(ex. 테일윈드 클래스)에 대응하기 위해서 계속해서 백엔드 엔지니어인 은찬님이 추가적인 hotfix를 진행해주시도 했다.
2. 느린 처리 속도

초기 코드를 작성할 때, 입력으로 받은 블로그 링크의 글 개수 및 글 내용을 수집할 때 requests 모듈을 사용해 데이터를 동기적으로 가져왔었다. 사실상 스크래퍼를 개발할 수 있는 시간이 매우 짧았기 때문에 티스토리 스크래퍼를 MVP로 개발할 때는 우선 돌아가는구나 했지만..😭 기존에 작성했던 코드는 느려도 너무 느리고 비효율적인 방식이 너무 많았다.
1. 동기적 요청 처리(requests)
requests.Session은 HTTP요청을 동기적으로 처리해, 한 번에 하나의 요청만 처리하고 응답이 올 때까지 다음 작업이 계속 대기 상태로 머물렀다. 많은 페이지를 탐색하거나 다수의 포스트를 요청할 때 당연하게도 응답 시간이 누적돼 처리 속도가 느려질 수 밖에 없었다.
(HTTP request-response는 네트워크 I/O 작업으로, 보통 응답 대기시간이 길어질 수 있기 때문에, 예를 들어 1개의 페이지 요청에 1초가 걸리면 100개 페이지 요청에 100초가 걸리는 상상)
response = session.get(post_url)다음과 같은 방식은 요청이 완료될 때까지 차단(blocking)되며, 다른 작업은 수행할 수 없다는 문제가 있었다.
2. 순차적 데이터 처리
초기 코드에서는 글 목록을 탐색한 후, 포스트별로 데이터를 순차적으로 가져왔다. 각 포스트에 대해 병렬 처리가 아닌 직렬로 처리됐기 때문에 처리 속도가 느릴 수 밖에 없었다.
3. 인위적인 지연 시간 (time.sleep)
time.sleep을 통해 서버로부터 차단되는 상황(429 Too Many Requests)을 막으려다보니 네트워크 응답 속도와 무관하게 실행 시간에 영향을 미칠 수 밖에 없었다.
초기에 테스트로 진행했던 약 70개의 글이 있던 블로그에 대해서 데이터를 수집하고 집계하는데만 약 8~10초가 걸리는 말도 안되는 상황이었다. (당연하게도 사용자에게는 블로그 분석을 한참동안 기다릴 인내심은 없다! 특히나 빨리빨리민족 한국인이라면 더더욱..!!)

블로그의 글이 많을 수록 처리 속도는 더욱 느릴 수 밖에 없었다. 또한 서비스는 단순 데이터 수집뿐만 아니라 집계, AI를 통한 각 글 분류, 사용자 페르소나 분류, 명언 추출 등을 진행해야 했기 때문에 최대한 데이터 수집 처리 속도를 줄여야만 했다.
위의 문제점들을 해결하기 위해 처음에 비동기 처리를 도입하고자 했다. 문제는 async를 사용했지만 계속해서 생각보다 속도 개선이 잘 되지 않았다. 결국, 혼자 계속 고민하기보다 은찬님에게 문제 상황을 공유했다.
3. 최고의 동료와 함께 문제 개선하기
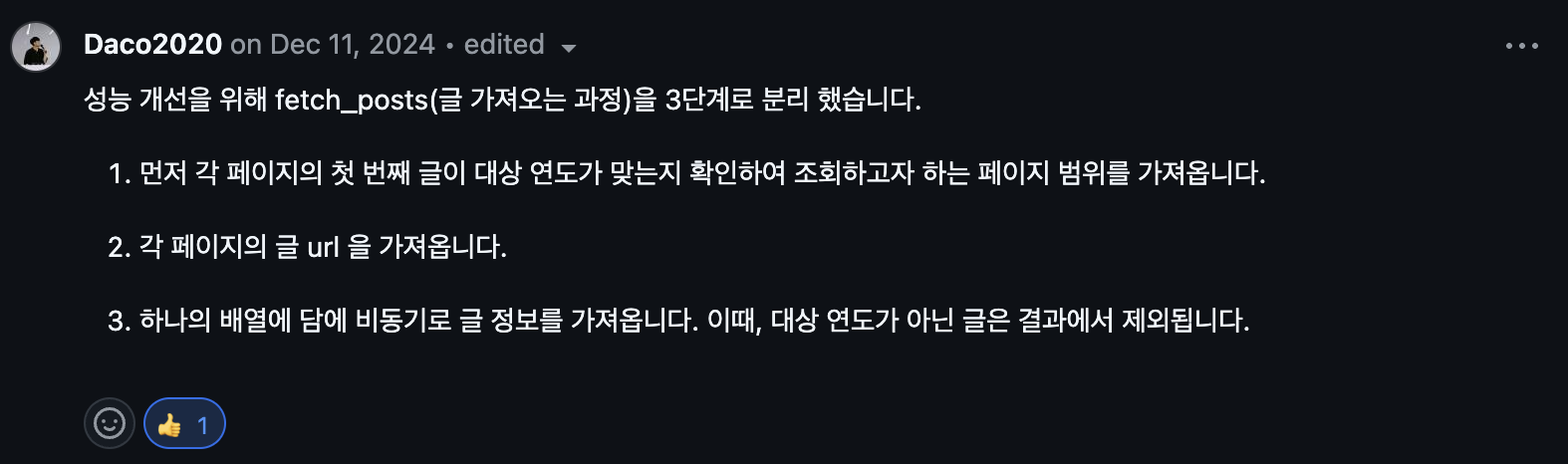
혼자 끙끙거리던 코드를 PR을 올리고 은찬님에게 PR리뷰를 받음으로써 성능을 개선할 수 있는 방법에 대해 배울 수 있었다.
구체적으로는 다음과 같은 세 가지 내용으로 정리할 수 있다.
1. 3단계로 작업 분리
fetch_posts를 3단계로 분리하여 불필요한 요청을 줄이고, 대상 범위 내에서만 효율적으로 작업을 수행하도록 개선했다.
- 1단계: 페이지 범위 탐색 (find_target_range)
각 페이지의 첫 번째 글이 대상 연도에 해당하는지 확인하여 조회해야 할 페이지 범위를 미리 설정한다.
-> 대상이 아닌 페이지를 탐색하지 않아도 되므로 불필요한 요청을 줄일 수 있다. - 2단계: 글 URL 수집 (_get_all_urls_by_page 또는 _get_all_urls_by_path)
각 페이지에서 글 URL을 추출하여 하나의 배열에 담는다.
-> 이 과정에서도 병렬 요청을 사용하여 속도를 높인다. - 3단계: 비동기적으로 글 정보 수집 (_fetch_posts)
수집한 URL 배열을 비동기로 처리하여 글 정보를 가져온다.
-> 대상 연도가 아닌 글은 바로 제외된다.
2. 비동기 작업 도입 (asyncio.gather) 및 requests 대신 httpx 사용
- 모든 네트워크 요청과 데이터 처리를 비동기로 수행한다.
- 병렬로 요청을 보내고, 응답을 기다리지 않고 다음 요청을 처리한다.
3. 결과 필터링을 요청 단계에서 적용
- 대상 연도에 맞지 않는 글은 요청 단계에서 걸러지도록 필터링한다.
- 비동기 함수인 fetch_post_details에서 대상 연도 체크를 추가해, 불필요한 데이터 처리를 감소시킨다.

이번에 은찬님의 피드백을 통해, 함수를 좀 더 쪼개고 asyncio.gather에 대해 알게 됐다.
그렇다면 왜 내가 처음에 async를 썼을 때는 성능 개선이 크게 되지 않았을까? asyncio.gather는 무엇일까?
기존의 코드는 아무리 async를 사용한들, requests 자체가 기본적으로 동기적 HTTP 요청을 처리하는 라이브러리이기 때문에 각 요청이 완료될 때까지 코드 실행이 멈추고, 네트워크 지연(RTT)이나 서버 응답 대기 시간이 길어지면 이 시간이 그대로 코드의 실행 시간에 반영됐다.
결과적으로, 비동기 함수(async def)를 사용해도 requests는 내부적으로 동기적 작업만 처리하므로 비동기 함수의 장점을 전혀 활용할 수 없었다.
따라서, 기존의 requests 라이브러리 대신 비동기 HTTP 요청을 처리하는 클라이언트인 httpx를 사용했다.
2. HTTP 비동기 클라이언트: httpx.AsyncClient
httpx.AsyncClient는 비동기 HTTP 요청을 지원하는 Python 라이브러리 httpx의 주요 클래스다. 표준 라이브러리 requests와 비슷한 방식으로 작동하지만, 비동기 I/O를 활용해 요청을 병렬 처리하거나 효율적으로 처리할 수 있다.
1. 비동기 I/O 처리
- httpx.AsyncClient는 Python의 비동기 기능 (asyncio)를 사용해 네트워크 요청과 같은 I/O 작업 중 대기 시간을 효율적으로 활용할 수 있다.
- 일반적으로 요청을 보내고 응답을 기다리는 동안 프로그램이 멈추지만, 비동기 클라이언트는 그 시간 동안 다른 작업을 처리할 수 있다.
2. 비동기 요청 메서드
httpx.AsyncClient는 HTTP 요청 메서드를 지원한다.
- get: 데이터를 가져오는 요청
- post: 데이터를 보내는 요청
- put, delete, patch 등: HTTP의 다양한 요청 메서드 지원
import httpx
import asyncio
async def fetch_data():
async with httpx.AsyncClient() as client:
response = await client.get("https://example.com")
print(response.text)
asyncio.run(fetch_data())
3. 세션 유지
- httpx.AsyncClient는 세션(session)을 유지한다.
- 동일한 연결을 재사용하기 때문에, 각 요청마다 새 연결을 생성하는 것보다 훨씬 빠르고 효율적이다.(쿠키, 인증, 헤더 등도 세션 동안 유지된다.)
또한, async와 달리 asyncio.gather를 사용하여 여러 비동기 작업(코루틴)을 병렬로 동시에 실행하고, 결과를 한꺼번에 반환했다. asyncio.gather는 각 네트워크 요청을 비동기적으로 수행해, 하나의 요청이 대기 상태에 있을 때 다른 요청이 실행된다.(예를 들어, 요청 A가 서버의 응답을 기다리는 동안, 요청 B, C 등 다른 요청을 보낼 수 있다.)
4. 배운 점
결과적으로, 위에서 소개한 방식들을 도입해 기존 실행시간의 절반인 약 4초 정도로 성능을 크게 개선할 수 있었다.
이전에도 여러 차례 스크래퍼를 개발해본 경험이 있었지만, 테블리에서는 사용자의 입력을 받는 즉시 빠르고 정확하게 스크래핑 결과를 처리해 보여줘야 했기 때문에 속도와 안정성이 무엇보다 중요했다. 특히, 티스토리의 경우 다양한 커스텀 스킨 때문에 HTML과 CSS 구조가 블로그 마다 달라, 이를 처리하는데 초기에 많은 시간이 소요되었다.
그러나 최고의 동료인 은찬님으로부터 httpx.AsyncClient와 asyncio.gather를 활용해 효율적인 비동기 처리 방식을 배우고 적용할 수 있었다. 이 과정에서 단순히 스크래퍼의 성능을 개선하는 것을 넘어, 비동기 프로그래밍의 원리를 더 이해하고 실제 프로젝트에 성공적으로 적용할 수 있었던 좋은 경험이었다. (빛은찬 최고)
다음 편에는 벨로그에서의 트러블 슈팅 경험을 정리해보려고 한다.
'Project > Potenday' 카테고리의 다른 글
| 10일 동안 밤새지 않는(?) 해커톤 포텐데이 412 1등 해버리기! (1) | 2024.12.22 |
|---|
이번 포스트는 포텐데이 412에서 1등을 했던 테블리의 핵심 기능을 개발하며 겪었던 문제 및 트러블 슈팅을 다뤄보려고 한다.
필요한 데이터 수집하기(티스토리)
테블리는 이름 그대로 '테크 블로그 리포트'라는 서비스다.
구체적으로는 블로그에 글을 발행하는 개발자들을 주 타겟으로 2024년 자신의 블로그에 대한 분석 및 연말 결산을 해주는 서비스이다.
사용자로부터 블로그의 링크를 입력으로 받으면, 사용자가 '2024년 총 몇개의 글을 썼는지', '주로 어떤 요일에 글을 썼는지', '글 별 평균 글자수', '글별 코드블럭 수', '글별 이미지 개수' 등을 보여주기 위해 해당 블로그로부터 필요 데이터를 빠르게 수집해서 통계를 보여줘야 했다.
이 때, 테블리에서 지원했던 플랫폼은 개발자들이 기술 블로그로 많이 사용하는 '티스토리'와 '벨로그'였는데 해당 플랫폼들에서 데이터를 수집하는 과정과 트러블 슈팅 과정에 대해 정리해보려고 한다.
먼저 이번 포스팅에서는 글또 기준, 기술 블로그로 가장 많이 사용하고 있던 티스토리에 대한 트러블 슈팅 과정을 다뤄봤다.
1. 너무 많은 (커스텀) 스킨
우선 티스토리의 경우, 벨로그와 달리 사용자가 여러 스킨을 선택할 수 있다.
기본적으로 티스토리에서 제공하는 스킨만 10가지이며, 이외에도 사용자가 직접 만든 커스텀 스킨(?)이 존재한다. (대표적으로는 heLLO 스킨)
문제는 기본 제공되는 티스토리 스킨이 개인적으로 HTML을 편집할 수 있다는 점이었다. 이로 인해, 블로그마다 HTML과 CSS 구조가 달라졌고, 데이터를 가져오는 방식을 각 스킨에 맞춰 개별적으로 처리해야 했다.
초기에는 팀원들의 블로그를 대상으로 처리 코드를 작성했고, 이후 티스토리에서 제공하는 스킨들, 유명 커스텀 스킨들로 처리 로직을 확장해나갔다.
1. POTENTIAL_CLASSES
POTENTIAL_CLASSES = [ 'post', 'list', 'list-list', 'article-type-common', 'post-item', 'article_content', 'content-list', 'index-item', re.compile(r'\blist\b.*content__index'), 'index-template', 'list content__index', 'list_content_text', 'item_category', 'link_thumb', 'list_content', 'index-article-item', 'one_article', 'fc-list-item', 'index-item-wrap', 'index-list-content', 'posts-index-item w-full h-auto border border-solid cursor-pointer relative' ]
다음과 같이 기본적으로 티스토리에서 제공하는 스킨과 유명 커스텀 스킨인 heLLO 등 최대한 모든 블로그 스킨에 대응하기 위해 다양한 스킨에서 자주 사용되는 클래스 이름을 POTENTIAL_CLASSES로 정의했다.
2. 각 스킨별 처리코드
@staticmethod def detect_post_elements(soup: BeautifulSoup): """ 글 정보를 포함할 가능성이 높은 후보를 탐색하여 반환. """ # 1. 우선적으로 ul > li > span.title 구조를 가진 요소 탐색 articles = soup.select('ul li:has(span.title)') uses_post_class = False # 2. 추가 탐색: 특정 클래스 기반으로 탐색 for class_name in POTENTIAL_CLASSES: if class_name == "post": # post 클래스 처리 post_elements = soup.select(".post") if post_elements: uses_post_class = True articles.extend(post_elements) break # 탐색 중단 (post 클래스가 우선순위 높음) elif class_name in ["list", "list-list"]: # list 및 list-list 클래스에서 li와 중첩된 div.item 탐색 articles.extend( soup.select(f".{class_name} ul li, .{class_name} ul div.item") ) elif isinstance(class_name, str): # 단일 클래스 탐색 articles.extend(soup.select(f".{class_name}")) elif isinstance(class_name, re.Pattern): # 정규식 기반 클래스 탐색 articles.extend(soup.find_all(class_=class_name))
(위 코드는 예시코드로 실제 코드는 좀 더 세부적인 처리 로직이 들어가있다.)
detect_post_elements 메서드에서 POTENTIAL_CLASSES에 정의된 클래스를 순차적으로 탐색하고, HTML 구조가 다를 수 있는 커스텀 스킨을 유연하게 처리하기 위해, 클래스 기반 탐색과 정규식 탐색을 포함시켜 최대한 모든 스킨에 대해 공통된 부분을 찾고, 예외는 별도로 대응하고자 했다.
해당 코드에는 포함돼있지 않지만, 서비스를 운영하며 추가적으로 발생한 버그들(ex. 테일윈드 클래스)에 대응하기 위해서 계속해서 백엔드 엔지니어인 은찬님이 추가적인 hotfix를 진행해주시도 했다.
2. 느린 처리 속도
초기 코드를 작성할 때, 입력으로 받은 블로그 링크의 글 개수 및 글 내용을 수집할 때 requests 모듈을 사용해 데이터를 동기적으로 가져왔었다. 사실상 스크래퍼를 개발할 수 있는 시간이 매우 짧았기 때문에 티스토리 스크래퍼를 MVP로 개발할 때는 우선 돌아가는구나 했지만..😭 기존에 작성했던 코드는 느려도 너무 느리고 비효율적인 방식이 너무 많았다.
1. 동기적 요청 처리(requests)
requests.Session은 HTTP요청을 동기적으로 처리해, 한 번에 하나의 요청만 처리하고 응답이 올 때까지 다음 작업이 계속 대기 상태로 머물렀다. 많은 페이지를 탐색하거나 다수의 포스트를 요청할 때 당연하게도 응답 시간이 누적돼 처리 속도가 느려질 수 밖에 없었다.
(HTTP request-response는 네트워크 I/O 작업으로, 보통 응답 대기시간이 길어질 수 있기 때문에, 예를 들어 1개의 페이지 요청에 1초가 걸리면 100개 페이지 요청에 100초가 걸리는 상상)
response = session.get(post_url)다음과 같은 방식은 요청이 완료될 때까지 차단(blocking)되며, 다른 작업은 수행할 수 없다는 문제가 있었다.
2. 순차적 데이터 처리
초기 코드에서는 글 목록을 탐색한 후, 포스트별로 데이터를 순차적으로 가져왔다. 각 포스트에 대해 병렬 처리가 아닌 직렬로 처리됐기 때문에 처리 속도가 느릴 수 밖에 없었다.
3. 인위적인 지연 시간 (time.sleep)
time.sleep을 통해 서버로부터 차단되는 상황(429 Too Many Requests)을 막으려다보니 네트워크 응답 속도와 무관하게 실행 시간에 영향을 미칠 수 밖에 없었다.
초기에 테스트로 진행했던 약 70개의 글이 있던 블로그에 대해서 데이터를 수집하고 집계하는데만 약 8~10초가 걸리는 말도 안되는 상황이었다. (당연하게도 사용자에게는 블로그 분석을 한참동안 기다릴 인내심은 없다! 특히나 빨리빨리민족 한국인이라면 더더욱..!!)
블로그의 글이 많을 수록 처리 속도는 더욱 느릴 수 밖에 없었다. 또한 서비스는 단순 데이터 수집뿐만 아니라 집계, AI를 통한 각 글 분류, 사용자 페르소나 분류, 명언 추출 등을 진행해야 했기 때문에 최대한 데이터 수집 처리 속도를 줄여야만 했다.
위의 문제점들을 해결하기 위해 처음에 비동기 처리를 도입하고자 했다. 문제는 async를 사용했지만 계속해서 생각보다 속도 개선이 잘 되지 않았다. 결국, 혼자 계속 고민하기보다 은찬님에게 문제 상황을 공유했다.
3. 최고의 동료와 함께 문제 개선하기
혼자 끙끙거리던 코드를 PR을 올리고 은찬님에게 PR리뷰를 받음으로써 성능을 개선할 수 있는 방법에 대해 배울 수 있었다.
구체적으로는 다음과 같은 세 가지 내용으로 정리할 수 있다.
1. 3단계로 작업 분리
fetch_posts를 3단계로 분리하여 불필요한 요청을 줄이고, 대상 범위 내에서만 효율적으로 작업을 수행하도록 개선했다.
- 1단계: 페이지 범위 탐색 (find_target_range)
각 페이지의 첫 번째 글이 대상 연도에 해당하는지 확인하여 조회해야 할 페이지 범위를 미리 설정한다.
-> 대상이 아닌 페이지를 탐색하지 않아도 되므로 불필요한 요청을 줄일 수 있다. - 2단계: 글 URL 수집 (_get_all_urls_by_page 또는 _get_all_urls_by_path)
각 페이지에서 글 URL을 추출하여 하나의 배열에 담는다.
-> 이 과정에서도 병렬 요청을 사용하여 속도를 높인다. - 3단계: 비동기적으로 글 정보 수집 (_fetch_posts)
수집한 URL 배열을 비동기로 처리하여 글 정보를 가져온다.
-> 대상 연도가 아닌 글은 바로 제외된다.
2. 비동기 작업 도입 (asyncio.gather) 및 requests 대신 httpx 사용
- 모든 네트워크 요청과 데이터 처리를 비동기로 수행한다.
- 병렬로 요청을 보내고, 응답을 기다리지 않고 다음 요청을 처리한다.
3. 결과 필터링을 요청 단계에서 적용
- 대상 연도에 맞지 않는 글은 요청 단계에서 걸러지도록 필터링한다.
- 비동기 함수인 fetch_post_details에서 대상 연도 체크를 추가해, 불필요한 데이터 처리를 감소시킨다.
이번에 은찬님의 피드백을 통해, 함수를 좀 더 쪼개고 asyncio.gather에 대해 알게 됐다.
그렇다면 왜 내가 처음에 async를 썼을 때는 성능 개선이 크게 되지 않았을까? asyncio.gather는 무엇일까?
기존의 코드는 아무리 async를 사용한들, requests 자체가 기본적으로 동기적 HTTP 요청을 처리하는 라이브러리이기 때문에 각 요청이 완료될 때까지 코드 실행이 멈추고, 네트워크 지연(RTT)이나 서버 응답 대기 시간이 길어지면 이 시간이 그대로 코드의 실행 시간에 반영됐다.
결과적으로, 비동기 함수(async def)를 사용해도 requests는 내부적으로 동기적 작업만 처리하므로 비동기 함수의 장점을 전혀 활용할 수 없었다.
따라서, 기존의 requests 라이브러리 대신 비동기 HTTP 요청을 처리하는 클라이언트인 httpx를 사용했다.
2. HTTP 비동기 클라이언트: httpx.AsyncClient
httpx.AsyncClient는 비동기 HTTP 요청을 지원하는 Python 라이브러리 httpx의 주요 클래스다. 표준 라이브러리 requests와 비슷한 방식으로 작동하지만, 비동기 I/O를 활용해 요청을 병렬 처리하거나 효율적으로 처리할 수 있다.
1. 비동기 I/O 처리
- httpx.AsyncClient는 Python의 비동기 기능 (asyncio)를 사용해 네트워크 요청과 같은 I/O 작업 중 대기 시간을 효율적으로 활용할 수 있다.
- 일반적으로 요청을 보내고 응답을 기다리는 동안 프로그램이 멈추지만, 비동기 클라이언트는 그 시간 동안 다른 작업을 처리할 수 있다.
2. 비동기 요청 메서드
httpx.AsyncClient는 HTTP 요청 메서드를 지원한다.
- get: 데이터를 가져오는 요청
- post: 데이터를 보내는 요청
- put, delete, patch 등: HTTP의 다양한 요청 메서드 지원
import httpx import asyncio async def fetch_data(): async with httpx.AsyncClient() as client: response = await client.get("https://example.com") print(response.text) asyncio.run(fetch_data())
3. 세션 유지
- httpx.AsyncClient는 세션(session)을 유지한다.
- 동일한 연결을 재사용하기 때문에, 각 요청마다 새 연결을 생성하는 것보다 훨씬 빠르고 효율적이다.(쿠키, 인증, 헤더 등도 세션 동안 유지된다.)
또한, async와 달리 asyncio.gather를 사용하여 여러 비동기 작업(코루틴)을 병렬로 동시에 실행하고, 결과를 한꺼번에 반환했다. asyncio.gather는 각 네트워크 요청을 비동기적으로 수행해, 하나의 요청이 대기 상태에 있을 때 다른 요청이 실행된다.(예를 들어, 요청 A가 서버의 응답을 기다리는 동안, 요청 B, C 등 다른 요청을 보낼 수 있다.)
4. 배운 점
결과적으로, 위에서 소개한 방식들을 도입해 기존 실행시간의 절반인 약 4초 정도로 성능을 크게 개선할 수 있었다.
이전에도 여러 차례 스크래퍼를 개발해본 경험이 있었지만, 테블리에서는 사용자의 입력을 받는 즉시 빠르고 정확하게 스크래핑 결과를 처리해 보여줘야 했기 때문에 속도와 안정성이 무엇보다 중요했다. 특히, 티스토리의 경우 다양한 커스텀 스킨 때문에 HTML과 CSS 구조가 블로그 마다 달라, 이를 처리하는데 초기에 많은 시간이 소요되었다.
그러나 최고의 동료인 은찬님으로부터 httpx.AsyncClient와 asyncio.gather를 활용해 효율적인 비동기 처리 방식을 배우고 적용할 수 있었다. 이 과정에서 단순히 스크래퍼의 성능을 개선하는 것을 넘어, 비동기 프로그래밍의 원리를 더 이해하고 실제 프로젝트에 성공적으로 적용할 수 있었던 좋은 경험이었다. (빛은찬 최고)
다음 편에는 벨로그에서의 트러블 슈팅 경험을 정리해보려고 한다.
'Project > Potenday' 카테고리의 다른 글
| 10일 동안 밤새지 않는(?) 해커톤 포텐데이 412 1등 해버리기! (1) | 2024.12.22 |
|---|