
해당 내용은 스파크 완벽 가이드를 학습하며 개인적 이해를 바탕으로 정리한 내용입니다.
잘못된 부분이 있다면 댓글로 알려주시면 감사하겠습니다!
스파크 완벽 가이드
오픈소스 클러스터 컴퓨팅 프레임워크인 스파크의 창시자가 쓴 스파크에 대한 종합 안내서입니다. 스파크 사용법부터 배포, 유지 보수하는 방법까지 포괄적으로 익힐 수 있습니다. 스파크 2의
www.hanbit.co.kr
2.1 스파크의 기본 아키텍처
한 대의 컴퓨터만으로는 더 이상 대규모 정보를 연산할 만한 자원이나 성능을 가지지 못한다.
설령, 연산을 할 수 있다고 하더라도 빅데이터를 처리하는 경우에는 많은 시간이 걸릴 수 밖에 없다.
컴퓨터 클러스터는 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용할 수 있게 한다.
그렇다면 클러스터는 무엇인가?
클러스터 이야기가 나오면 노드(Node)도 꼭 함께 나오는데 이 개념을 먼저 살펴보자.
- 클러스터(Cluster)는 여러 대의 컴퓨터(서버)가 네트워크로 연결돼 하나의 시스템처럼 작동하는 것을 말한다.
- 노드(Node)는 클러스터를 구성하는 각각의 컴퓨터를 말한다. 각 노드는 자체적인 처리 능력, 메모리, 저장 공간 등을 가지고 있고 클러스터의 일부로서 작업을 수행한다.
쉬운 예시를 들어보면, 요즘 나는 도서관에 자주가니 도서관으로 예를 들어보겠다.

도서관 자체를 하나의 '클러스터'로 생각할 수 있다.
도서관은 여러 명의 사서(컴퓨터 또는 노드)를 가지고 있고, 각각의 사서는 자신에게 할당된 책을 정리하는 작업을 담당한다.
예를 들어, 한 사서는 소설 책을, 다른 사서는 과학 책을 정리한다. 이처럼 각 노드는 독립적으로 작업을 수행하지만, 최종 목표는 같은 클러스터(도서관) 내에서 서로 협력하여 효율성을 높이며 도서관의 책을 전체적으로 정리하는 것이다.
스파크의 동작원리도 위와 비슷하게 이루어진 프레임워크다.
대규모 데이터를 처리할 때, 스파크 클러스터의 각 노드는 데이터의 일부를 담당하여 처리한다.
각 노드들은 각자의 작업을 독립적으로 수행하지만, 최종 결과는 하나의 큰 목표를 향해 통합되는 형태로 진행된다.
스파크가 연산에 사용할 클러스터는 다음과 같은 클러스터 매니저에서 관리한다.

1. Spark Standalone
- 특징
- 스파크에 내장된 기본 클러스터 매니저
- 스파크 애플리케이션을 실행하기 위해 별도의 클러스터 매니저가 필요하지 않음
- 간단한 설치와 구성으로 스파크 클러스터를 구축 가능
- 장점
- 독립적으로 실행되며, 다른 클러스터 관리 시스템에 의존하지 않음
- 작은 규모의 클러스터나 테스트 환경에서 사용하기 적합
- 단점
- 고급 리소스 관리 및 작업 스케줄링 기능이 부족
- 대규모 분산 환경에서는 제한적
- 사용 사례
- 개발, 테스트 또는 소규모 클러스터에서 스파크만 사용하는 경우
2. Hadoop YARN
- 특징
- Hadoop Distributed File System (HDFS)와 통합된 리소스 관리 플랫폼
- Hadoop 생태계와 잘 연동되며, 스파크가 YARN 위에서 실행 가능
- 스파크 애플리케이션은 YARN의 리소스 관리 시스템에 의해 리소스를 요청하고 사용
- 장점
- 데이터와 계산이 가까운 위치에서 실행되므로 데이터 로컬리티가 뛰어남
- 대규모 클러스터에서 효율적인 리소스 공유와 관리 가능
- Hadoop 기반 인프라를 사용하는 환경에서 적합
- 단점
- 설정이 복잡할 수 있으며, YARN 자체의 오버헤드가 발생
- 비-Hadoop 환경에서는 적합하지 않음
- 사용 사례
- Hadoop 기반 클러스터에서 스파크 애플리케이션을 실행할 때.
3. Mesos
- 특징
- 분산 시스템 리소스를 관리하기 위한 범용 클러스터 관리 플랫폼
- 여러 애플리케이션(예: Spark, Hadoop, Kafka 등)을 하나의 클러스터에서 동시에 실행 가능
- 스파크는 Mesos 위에서 실행되며, 리소스를 동적으로 요청하고 사용할 수 있음
- 장점
- 다양한 워크로드(스파크 외에도)를 지원하며, 유연한 리소스 할당 가능
- 리소스 분리와 공유를 통해 클러스터 효율성을 극대화
- 대규모 멀티테넌트 환경에서 적합
- 단점
- 설정 및 운영이 복잡하며, Mesos 자체의 학습 곡선이 있음
- YARN에 비해 사용 빈도가 낮아 커뮤니티 지원이 부족할 수 있음
- 사용 사례
- 다양한 분산 애플리케이션이 혼재하는 멀티테넌트 환경
| 특징 | Spark Standalone | Hadoop YARN | Mesos |
| 리소스 관리 | 단순, 스파크 전용 | YARN에서 리소스 관리 | 여러 애플리케이션에서 리소스 공유 |
| 복잡도 | 설정 간단 | 설정 복잡 | 설정 복잡 |
| 확장성 | 소규모 클러스터에 적합 | 대규모 데이터 처리에 적합 | 대규모 멀티테넌트 환경에 적합 |
| 사용 사례 | 테스트, 소규모 클러스터 | Hadoop 기반 환경 | 다양한 분산 시스템 환경 |
사용자는 클러스터 매니저에 Spark application을 제출(Submit)하고, 이를 받은 클러스터 매니저는 Spark application 실행에 필요한 자원을 할당해준다.
2.1.1 스파크 애플리케이션
스파크 애플리케이션은 분산 데이터 처리를 위해 스파크 프레임 워크를 사용하는 프로그램으로, driver process와 다수의 executor process로 구성된다.
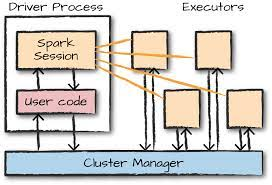
드라이버 프로세스(Driver Process, Spark Driver)
- 드라이버 프로세스는 한 개의 노드에서 실행된다. 스파크 애플리케이션의 '마스터 노드' 즉, 지휘자 역할(중앙 처리장치)을 한다. main() 함수를 실행하여 사용자가 작성한 스파크 작업을 관리하고 조정(Spark Context를 시작, 제출된 애플리케이션 실행)한다.
- 작업을 초기화하고, 작업 흐름을 계획하며, 클러스터 매니저(Spark Master)와 통신하여 각 익스큐터 프로세스에 작업을 할당하고, 전체 애플리케이션의 상태를 모니터링하는 역할을 담당한다.
- 드라이버 프로세스는 전체 애플리케이션의 성공 및 실패를 관리하고, 작업이 완료된 후 결과를 수집하여 최종 결과를 반환한다.
익스큐터 프로세스(Executor Process)
- 익스큐터 프로세스는 클러스터 내의 '워커 노드'(작업자)에 해당되며, 실제 데이터 처리 작업을 수행한다.
- 각 익스큐터는 스파크 작업의 일부를 독립적으로 처리하며, 자체 메모리와 계산 자원을 갖고 있어 병렬로 데이터 처리 작업을 수행한다.
- 익스큐터는 드라이버로부터 받은 작업을 실행하고, 처리 결과를 드라이버(엄밀히 말하면, 드라이버 내의 spark context)에게 보고한다.
또한, 필요에 따라 데이터의 일부를 메모리에 유지하며, 다른 익스큐터와도 데이터를 교환할 수 있다.
- Spark Job을 Submit 할 때, 익스큐터의 수를 지정할 수 있다. 각 익스큐터마다 몇 개의 (virtual) core를 사용할지, 얼마의 RAM을 사용할지 지정할 수 있다.
클러스터 매니저(Cluster Manager)
- Spark Driver가 요청한 리소스를 할당하고, Driver가 요청한 프로그램을 Worker node에서 실행할 수 있는 instruction을 제공한다.
- Cluster manager는 Executor의 자원 사용, 성능을 트래킹하고, Job이 끝나면 Driver에게 작업의 종료를 알린다. 작업 도중 Worker Node가 실패하거나 삭제되면, Cluster Manager는 같은 작업을 다른 노드에 할당해서 작업이 이어지도록 한다.
위 내용들을 정리해보자면, 클러스터의 각 노드는 드라이버 프로세스와 익스큐터 프로세스가 실행되는 환경을 제공한다.
작업을 할당하는 주체인 드라이버 프로세스는 전체 애플리케이션을 관리하고 지휘하는 역할이며, 익스큐터 프로세스는 실제로 데이터를 처리하는 작업을 담당한다.
클러스터 매니저는 노드 및 리소스를 관리하는 역할을 수행한다. 즉, 작업 자체를 할당하지 않고, Spark Driver가 Executor에게 작업을 할당할 수 있도록 필요한 리소스와 환경을 제공하는 역할을 한다.
An overview of how spark works

Step 1: Spark Submit
사용자는 spark-submit 명령을 사용하여 Spark 애플리케이션을 제출한다. 로컬 모드에서는 Spark Driver가 로컬 컴퓨터에서 바로 실행되고, 클러스터 모드에서는 클러스터 매니저가 클러스터의 노드 중 하나에서 Spark Driver를 시작하며, 필요한 리소스를 할당한다.
(로컬 모드에서는 모든 리소스도 로컬에서 관리되는 반면, 클러스터 모드에서는 클러스터 매니저가 여러 노드의 리소스를 조정하며 분산 처리를 통해 작업을 나누어 실행한다.) 추가적으로 Spark Driver는 Spark Context를 시작하고, 애플리케이션을 초기화하며, 전체 실행을 관리하고 담당한다.
Step 2: Logical and Physical Plans

드라이버는 제출된 코드를 분석해 논리적 계획(Logical plan)을 생성하고, 이를 최적화해 물리적 계획(Physical plan)으로 변환한다.
물리적 계획은 실제로 애플리케이션의 실행을 지시하는 역할을 한다.
이 계획에 따라 각 Job은 DAG(Directed Acyclic Graph) 형식으로 여러 stage로 나뉘고, 각 stage는 다시 작은 task 단위로 세분화된다. 이 task들은 클러스터의 여러 익스큐터에 의해 실행되도록 task scheduler에 의해 스케줄링된다.
Step 3: Resource Negotiation
Spark Driver(Spark Context)는 클러스터 매니저와 상호작용해 task를 실행하는데 필요한 컴퓨팅 리소스(예: CPU, 메모리)를 할당 받는다.
Step 4: Instruction to Available Worker
클러스터 매니저는 사용 가능한 워커 노드에 작업을 지시한다. 이는 드라이버로부터 받은 실행 계획에 따라 각 워커 노드의 익스큐터에 특정 작업을 할당하는 과정을 포함한다.
Step 5: Executors Register with Driver
각 워커 노드의 익스큐터는 스파크 드라이버에 자신을 등록한다. 이를 통해 드라이버는 사용 가능한 익스큐터의 정보를 알고, 앞으로의 작업을 효과적으로 할당할 수 있다.
Step 6: Driver Monitor and Plans for Future Tasks
드라이버는 실행 중인 작업을 모니터링하고, 향후 수행할 작업에 대한 계획을 수립한다. 이를 통해, 작업의 진행 상황을 추적하고, 필요에 따라 추가 작업을 스케줄링하는 과정을 포함한다.
2.2 스파크의 다양한 언어 API
- 스칼라(스파크의 기본 언어), 자바, 파이썬, SQL, R

Spark 코드를 실행할 때, SparkSession은 주요 진입점 역할을 한다.
이 SparkSession은 JVM(Java Virtual Machine) 위에서 실행되고, 이를 통해 스파크 애플리케이션의 세션을 관리한다.
Python, R로 작성한 코드 역시 스파크의 다양한 API와 연동돼 JVM에서 실행할 수 있는 코드로 변환된다.
2.3 스파크 API
- 저수준 비구조적(Unstructured) API
- 고수준 구조적(Structured) API
2.4 스파크 시작하기
2.5 SparkSession
SparkSession은 스파크 애플리케이션의 드라이버 프로세스에서 실행되는 중요한 컴포넌트이다.
SparkSession 인스턴스는 하나의 스파크 애플리케이션에 대응하며, 사용자가 정의한 처리 명령(코드)을 클러스터에서 실행한다.
SparkSession은 SparkContext를 포함하고 있다. 즉, SparkSession을 생성하면 그 내부에서 SparkContext도 생성되어 클러스터와의 연결을 관리한다. Spark 2.x부터는 SparkSession이 기본 진입점으로 사용되며, SparkContext는 내부적으로 처리된다 .
# SparkSession 생성
spark = SparkSession.builder.appName("example").getOrCreate()
# SparkContext에 접근 (SparkSession에서 제공)
sc = spark.sparkContext
- Spark Context란?
- 스파크 애플리케이션의 초기 진입점으로, 클러스터와 연결하고 작업을 제출하는 데 사용된다.
- RDD(Resilient Distributed Dataset)를 다루는 데 필요한 주요 인터페이스를 제공한다.
- 역할
- 클러스터 매니저(YARN, Mesos 등)와 연결
- RDD를 생성하고 작업(Task)을 클러스터에 분배
- 분산 작업 실행 및 결과 수집
- 제한점
- Spark Context만으로는 데이터프레임(DataFrame)이나 SQL 처리가 어렵다.
- 초기엔 RDD 중심으로 설계되었기 때문에, 데이터프레임과 데이터셋(DataSet)이 나오기 전까지만 사용됐다.

2.6 DataFrame

가장 대표적인 구조적 API로, DataFrame은 테이블의 데이터를 Row(로우)와 Column(컬럼)으로 표현한다.
컬럼과 컬럼의 타입을 정의한 목록을 스키마라고 부르며, Pandas의 DataFrame의 개념과 비슷하다.
하지만, 파이썬과 R의 DataFrame은 일반적으로 분산 컴퓨터가 아닌 단일 컴퓨터에만 존재하지만, 스파크 DataFrame은 수천 대의 컴퓨터에 분산돼있다. 그 이유는 단일 컴퓨터에 저장하기에는 데이터가 너무 크거나 계산에 오랜 시간이 걸릴 수 있기 때문이다.
스파크는 파이썬과 R 언어를 모두 지원하기 때문에 파이썬 Pandas 라이브러리의 DataFrame과 R의 DataFrame을 스파크 DataFrame으로 쉽게 변환할 수 있다.
2.6.1 Partition

위의 전체 데이터셋을 P1, P2, P3 세 부분(=파티션)으로 나누었고, 각 파티션을 Executor 1, Executor 2, Executor 3이 처리한다.
즉, 스파크는 모든 익스큐터가 병렬로 작업을 수행할 수 있도록 Partition(파티션)이라 불리는 청크 단위로 데이터를 분할한다.
1. 병렬 처리: 데이터가 파티션으로 나누어지면, 각 파티션은 독립적으로 다른 익스큐터에 의해 처리될 수 있다.
2. 작업 분산: 파티션이 다양한 익스큐터에 할당되면, 모든 익스큐터가 균등하게 작업을 수행하게 된다.
3. 처리 속도 향상: 데이터를 파티션으로 나눔으로써, 각 익스큐터는 데이터의 작은 부분만을 처리하므로 전체적인 처리 속도가 향상된다.
2.7 Transformation
스파크의 핵심 데이터 구조는 불변성을 가진다.
데이터 구조를 변경하려면 원하는 변경 방법을 스파크에 알려줘야 하며, 이 때 사용하는 명령을 Transformation이라 부른다.
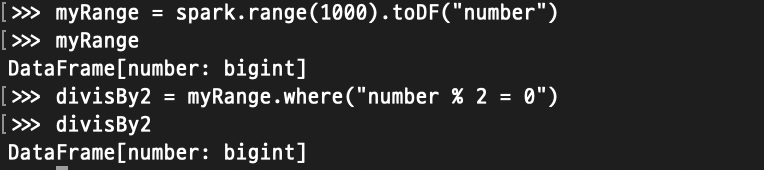
해당 코드를 실행해도 (Pandas의 DataFrame과 달리) 결과는 출력되지 않는다.
추상적인 트랜스포메이션만 지정한 상태이기 때문에, 액션을 호출하지 않으면 스파크는 실제 트랜스포메이션을 수행하지 않는다.
Transformation의 유형에는 두 가지가 있다.
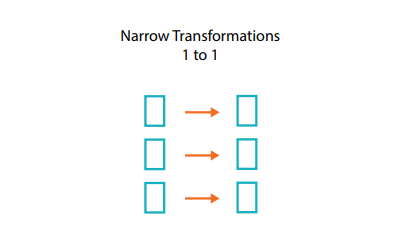
1. 좁은 트랜스포메이션(Narrow Transformation)
각 입력 파티션이 하나의 출력 파티션에만 영향을 미친다. (ex. map, mapPartition, flatMap, filter, union, contatins...)
다른 노드의 데이터를 필요로 하지 않으므로 데이터 이동이 필요하지 않다.
예를 들어, 필터 함수는 주어진 데이터 세트에서 특정 조건을 만족하는지 단일 레코드의 값만 확인하면 되기 때문에 narrow transformations 중 하나이다.
2. 넓은 트랜스포메이션(Wide Transformation)
하나의 입력 파티션이 여러 출력 파티션에 영향을 미친다. (ex. groupBy, join, repartition)
한 작업이 다른 노드에 있는 데이터를 필요로 할 때 Wide Transformation이 발생한다. 여러 데이터 파티션 간의 교차 의존성이 있기 때문에, 연관된 데이터를 한 곳에 모아 처리해야 한다.
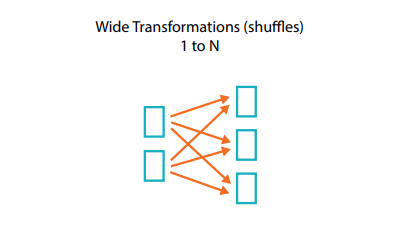
특히, 셔플의 경우 필요한 데이터를 다른 노드로부터 가져와 적절한 노드에서 데이터를 재조합하는 과정이다.
여러 노드 간에 데이터를 재분배하는 과정에서 대량의 데이터가 네트워크를 통해 이동해야 하기 때문에, 시스템 성능에 영향을 줄 수 있다.
셔플된 데이터는 일반적으로 디스크에 임시로 저장되며, 이는 필요한 데이터를 다른 노드로 전송하기 전에 중간 결과를 보관하기 위함이다.
이 과정에서 디스크 I/O가 발생할 수 있다.
2.7.1 Lazy Evaluation(지연 연산)
스파크가 연산 그래프를 처리하기 직전까지 기다리는 동작 방식을 의미한다.
스파크는 특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고, 원시 데이터에 적용할 트랜스포메이션의 실행 계획을 생성한다.
2.8 Action
Transformation을 통해 세운 논리적 실행 계획을 실제 연산으로 수행하려면 Action 명령을 내려야 한다.
액션의 예로는 가장 단순한 count 메서드와 같은 것이 있다.
액션을 지정하면 스파크 잡(job)이 시작된다.
2.9 Spark UI
Spark UI를 통해 스파크 잡(Job)의 진행 상황을 모니터링 할 수 있다. Spark UI는 드라이버 노드의 4040 포트로 접속이 가능하다.
로컬 모드에서 스파크를 실행했다면 Spark UI 주소는 http://localhost:4040 으로 다음과 같이 확인할 수 있다.

2.10 종합 예제
미국 교통통계국의 항공 운항 데이터 중 일부를 스파크로 분석해볼 수 있는 실습해보기
코드는 여기서 확인할 수 있으니 굳이 블로그에 옮겨적진 않겠다.
스파크에서 데이터는 SparkSession의 DataFrameReader 클래스를 사용해 읽을 수 있다.
우리가 알고 있는 Pandas의 DataFrame과 달리, 스파크의 DataFrame은 불특정 다수의 로우와 컬럼을 가진다.
데이터를 읽는 과정이 Lazy Evaluation 형태의 트랜스포메이션이기 때문에 로우의 수를 알 수 없다.
번외. Spark 사용시 주의할 점
1. 드라이버의 단일 실패 지점(SPOF) 문제
SPOF는 Single Point of Failure의 약자로, 시스템 내에서 단일 실패 지점을 의미한다. 어떤 특정 구성 요소가 고장 났을 때 전체 시스템이 작동하지 못하게 되는 문제를 말한다.
Client-Mode에서의 드라이버
: Spark의 드라이버는 하나의 JVM(Java Virtual Machine)으로 운영되며, 이 드라이버가 실패하면 전체 애플리케이션이 중단될 수 있다. 즉, 드라이버는 작업 결과를 취합하고 관리하는 중추적인 역할을 하기 때문에, 작업 부하가 많은 경우 오버헤드(OOM)로 인해 드라이버가 다운될 수 있다. 이 경우 자동으로 드라이버를 복구하는 기능은 없기 때문에, 드라이버 프로세스를 지속적으로 모니터링하고 문제가 발생하면 즉시 대처할 방법이 필요하다.
Cluster-Mode에서의 드라이버
: Cluster-Mode에서는 드라이버가 실행되는 컨테이너가 실패할 경우 자동으로 Driver가 자동으로 재시작된다. 하지만, 재시작 과정에서 드라이버에 의해 저장된 데이터가 보존된다는 보장이 없다. 이 또한 드라이버가 SPOF로 작용할 수 있으므로, 재시작시 데이터 손실 없이 운영될 수 있도록 설계해야 한다.
2. 익스큐터의 수와 리소스 관리
익스큐터 수의 조절
: 익스큐터의 수를 늘리면 데이터 처리의 병렬성이 증가하고, 작업 처리 속도가 빨라질 수 있다. 하지만, 데이터 양에 비해 과도하게 많은 익스큐터를 사용하면 오히려 네트워크 트래픽이 증가하고 셔플 데이터의 양이 늘어나면서 전체 성능이 저하될 수 있다.
3. 멱등성(Idempotency)
작업의 재처리 고려
: Spark 작업은 언제든지 중단되고 재시작될 수 있으므로, 한 번의 실행 결과가 같게 유지되도록 멱등성(작업을 반복해도 결과가 동일하게 유지되도록 하는 성질)을 확보해야 한다.
스트리밍 작업의 상태 관리
: context가 필요한 스트리밍 작업에서는 at least once, at most once, exactly once의 처리가 보장되는 상태 관리 전략을 고려해야 한다. checkpoint 기능을 활용해 애플리케이션의 중간 상태를 안정적으로 저장하고, 문제 발생 시 이를 복구할 수 있도록 하는 것이 좋다.
Reference
'Data Engineering > Spark' 카테고리의 다른 글
| 데이터가 Even하게 분산되지 않았어요, Spark에서 Data Skew 해결하기! (0) | 2024.10.27 |
|---|---|
| [Spark 완벽 가이드] 3. 스파크 기능 둘러보기 (0) | 2024.05.26 |