
✨ 배경
최근 Google Sheet로 수집되고 있는 데이터를 정기적으로 AWS S3에 저장하고, Athena나 Glue를 통해 분석할 수 있는 구조를 만드는 작업이 필요해졌다. 단순히 CSV 파일을 저장하는 수준이 아니라, 데이터 레이크 환경에서 관리할 수 있도록 Parquet 포맷으로 저장하고, 타입 안정성까지 고려해야 했다.
이를 위해 Google Sheets API v4를 활용해 데이터를 안정적으로 가져오고, Pandas → Parquet → Athena까지 연동되는 파이프라인을 구성하게 되었다.
📌 목표
- Google Spreadsheet 데이터를 읽어옴
- Pandas DataFrame으로 변환
- awswrangler.s3.to_parquet()을 사용해 S3에 Parquet 포맷으로 저장
- Glue/Athena에서 바로 분석 가능한 형태로 활용
🛠 사용한 도구
- Google Sheets API v4
- pandas.read_csv() (Google Sheet export 용도)
- pandas, awswrangler, boto3
🪜 Step-by-step
Google Cloud 콘솔에서 OAuth 2.0 Client ID를 발급받고, 아래와 같은 흐름으로 API를 사용해 Google Sheet 데이터를 읽어왔다
1. 인증 준비
- Google Cloud Console에서 OAuth Client 생성
- Scopes: https://www.googleapis.com/auth/spreadsheets
- 인증 후 생성된 token.json으로 자동 재사용
2. Google Spreadsheet에서 데이터 가져오기
from google.oauth2.credentials import Credentials
from googleapiclient.discovery import build
# 상수 설정
SCOPES = ['https://www.googleapis.com/auth/spreadsheets']
SPREADSHEET_ID = 'your-spreadsheet-id'
RANGE = 'Sheet1!A:E'
TOKEN_PATH = 'google-sheet-api-token.json'
# 인증 및 서비스 객체 생성
credentials = Credentials.from_authorized_user_file(TOKEN_PATH, SCOPES)
service = build('sheets', 'v4', credentials=credentials)
# 데이터 읽기
result = service.spreadsheets().values().get(
spreadsheetId=SPREADSHEET_ID, range=RANGE).execute()
values = result.get('values', [])3. Pandas DataFrame으로 변환
import pandas as pd
# 첫 행은 컬럼명
header = values[0]
rows = values[1:]
df = pd.DataFrame(rows, columns=header)4. S3에 Parquet로 저장하기
import awswrangler as wr
wr.s3.to_parquet(
df=df,
path='s3://your-bucket/path/to/data/',
dataset=True,
mode='overwrite', # 'append'도 가능
partition_cols=None, # 필요 시 파티션 컬럼 지정
)5. 저장된 파일 확인
S3에서 Parquet 파일이 저장된 것을 확인할 수 있으며, Athena/Glue에서도 바로 테이블을 생성해 조회 가능하다.
⚠️ 예상치 못한 문제: 컬럼 타입 호환성
작업 중 가장 큰 시행착오는 컬럼의 데이터 타입을 고려하지 않았던 점이었다.
Google Sheet에서는 숫자처럼 보이는 값이라도 문자열로 저장되는 경우가 많다. 예를 들어 아래와 같은 질문을 받고 문제를 인지하게 되었다.
"Google Sheet에서 id 컬럼이 1, 2로 보이는데, Glue 테이블에서 이게 정말 숫자(int)로 인식되나요?"
처음에는 Pandas에서 자동으로 타입을 잘 추론해줄 것이라 생각했지만, 실제로는 그렇지 않았다. 특히 Google Sheet에서 값을 입력할 때 string과 boolean이 섞여 있는 경우, Pandas에서는 object로 인식되고, 이로 인해 Parquet 저장 시 의도하지 않은 타입으로 저장되거나 Athena에서 인식 불가한 스키마가 생길 수 있었다.
🔍 타입 지정 방법
awswrangler.s3.to_parquet()에서는 dtype 파라미터를 통해 컬럼 타입을 명시적으로 지정할 수 있다.
>>> import awswrangler as wr
>>> import pandas as pd
>>> wr.s3.to_parquet(
... df=pd.DataFrame({
... 'col': [1, 2, 3],
... 'col2': ['A', 'A', 'B'],
... 'col3': [None, None, None]
... }),
... path='s3://bucket/prefix',
... dataset=True,
... database='default', # Athena/Glue database
... table='my_table' # Athena/Glue table
... dtype={'col3': 'date'}
... )
{
'paths': ['s3://.../x.parquet'],
'partitions_values: {}
}그러나 실무에서는 Google Sheet의 특성상 동일 컬럼에 다양한 타입이 섞여 있는 경우가 빈번하다.
예를 들어, 원래는 True/False만 있어야 하는 boolean 컬럼에 'yes', 'N/A' 같은 문자열이 입력되는 경우, Pandas는 해당 컬럼을 object로 인식하고, Glue에서는 이를 string으로 받아들이게 된다.
이외에도, pandas dataframe의 데이터 값들이 어떤 값들로 변환되는지 소스코드를 뜯어보았다.
🔬 내부 동작 분석: Pandas → PyArrow → Athena 타입 변환
내부적으로 Pandas DataFrame을 S3에 Parquet로 저장할 때, awswrangler는 pyarrow를 이용해 타입을 먼저 추론하고, 이후 Glue/Athena에서 인식 가능한 타입으로 변환한다. 이때 사용되는 로직은 pyarrow_types_from_pandas() → pyarrow2athena()로 이어지는 체인으로, 컬럼별 타입이 자동으로 정해진다.
다만 object나 empty column이 있을 경우 의도하지 않은 string 혹은 null로 저장될 수 있어, df.astype()을 통한 사전 지정이 중요하다.
1. pyarrow_types_from_pandas()
Pandas DataFrame → PyArrow DataType 변환
@engine.dispatch_on_engine
def pyarrow_types_from_pandas( # noqa: PLR0912,PLR0915
df: pd.DataFrame, index: bool, ignore_cols: list[str] | None = None, index_left: bool = False
) -> dict[str, pa.DataType]:
"""Extract the related Pyarrow data types from any Pandas DataFrame."""
# Handle exception data types (e.g. Int64, Int32, string)
ignore_cols = [] if ignore_cols is None else ignore_cols
cols: list[str] = []
cols_dtypes: dict[str, pa.DataType | None] = {}
for name, dtype in df.dtypes.to_dict().items():
dtype_str = str(dtype)
if name in ignore_cols:
cols_dtypes[name] = None
elif dtype_str == "Int8":
cols_dtypes[name] = pa.int8()
elif dtype_str == "Int16":
cols_dtypes[name] = pa.int16()
elif dtype_str == "Int32":
cols_dtypes[name] = pa.int32()
elif dtype_str == "Int64":
cols_dtypes[name] = pa.int64()
elif dtype_str == "float32":
cols_dtypes[name] = pa.float32()
elif dtype_str == "float64":
cols_dtypes[name] = pa.float64()
elif dtype_str == "string":
cols_dtypes[name] = pa.string()
elif dtype_str == "boolean":
cols_dtypes[name] = pa.bool_()
else:
cols.append(name)
# Filling cols_dtypes
for col in cols:
_logger.debug("Inferring PyArrow type from column: %s", col)
try:
schema: pa.Schema = pa.Schema.from_pandas(df=df[[col]], preserve_index=False)
except pa.ArrowInvalid as ex:
cols_dtypes[col] = process_not_inferred_dtype(ex)
except TypeError as ex:
msg = str(ex)
if " is required (got type " in msg:
raise TypeError(
f"The {col} columns has a too generic data type ({df[col].dtype}) and seems "
f"to have mixed data types ({msg}). "
"Please, cast this columns with a more deterministic data type "
f"(e.g. df['{col}'] = df['{col}'].astype('string')) or "
"pass the column schema as argument"
f"(e.g. dtype={{'{col}': 'string'}}"
) from ex
raise
else:
cols_dtypes[col] = schema.field(col).type- 이 함수는 Pandas DataFrame의 각 컬럼을 보고 적절한 PyArrow 데이터 타입으로 추론한다.
- 내부적으로 pa.Schema.from_pandas()를 쓰며, df.dtypes를 직접 검사해서 Int64 → pa.int64() 같은 매핑을 수행한다.
2. pyarrow2athena()
PyArrow DataType → Athena 타입 문자열 변환
def pyarrow2athena( # noqa: PLR0911,PLR0912
dtype: pa.DataType, ignore_null: bool = False
) -> str:
"""Pyarrow to Athena data types conversion."""
if pa.types.is_int8(dtype):
return "tinyint"
if pa.types.is_int16(dtype) or pa.types.is_uint8(dtype):
return "smallint"
if pa.types.is_int32(dtype) or pa.types.is_uint16(dtype):
return "int"
if pa.types.is_int64(dtype) or pa.types.is_uint32(dtype):
return "bigint"
if pa.types.is_uint64(dtype):
raise exceptions.UnsupportedType("There is no support for uint64, please consider int64 or uint32.")
if pa.types.is_float32(dtype):
return "float"
if pa.types.is_float64(dtype):
return "double"
if pa.types.is_boolean(dtype):
return "boolean"
if pa.types.is_string(dtype) or pa.types.is_large_string(dtype):
return "string"
if pa.types.is_timestamp(dtype):
return "timestamp"
if pa.types.is_date(dtype):
return "date"
if pa.types.is_binary(dtype) or pa.types.is_fixed_size_binary(dtype):
return "binary"
if pa.types.is_dictionary(dtype):
return pyarrow2athena(dtype=dtype.value_type, ignore_null=ignore_null)
if pa.types.is_decimal(dtype):
return f"decimal({dtype.precision},{dtype.scale})"
if pa.types.is_list(dtype) or pa.types.is_large_list(dtype):
return f"array<{pyarrow2athena(dtype=dtype.value_type, ignore_null=ignore_null)}>"
if pa.types.is_struct(dtype):
return (
f"struct<{','.join([f'{f.name}:{pyarrow2athena(dtype=f.type, ignore_null=ignore_null)}' for f in dtype])}>"
)
if pa.types.is_map(dtype):
return f"map<{pyarrow2athena(dtype=dtype.key_type, ignore_null=ignore_null)},{pyarrow2athena(dtype=dtype.item_type, ignore_null=ignore_null)}>"
if dtype == pa.null():
if ignore_null:
return ""
raise exceptions.UndetectedType("We can not infer the data type from an entire null object column")
raise exceptions.UnsupportedType(f"Unsupported Pyarrow type: {dtype}")- 이 함수는 위에서 얻은 pa.DataType 값을 받아 Athena에서 사용하는 문자열 타입으로 변환한다. 예: pa.int64() → "bigint"
athena_types_from_pandas()
전체 흐름을 처리해주는 메인 함수!
Pandas DataFrame → Athena 타입 딕셔너리까지 한 번에 처리함
def athena_types_from_pandas(
df: pd.DataFrame, index: bool, dtype: dict[str, str] | None = None, index_left: bool = False
) -> dict[str, str]:
"""Extract the related Athena data types from any Pandas DataFrame."""
casts: dict[str, str] = dtype if dtype else {}
pa_columns_types: dict[str, pa.DataType | None] = pyarrow_types_from_pandas(
df=df, index=index, ignore_cols=list(casts.keys()), index_left=index_left
)
athena_columns_types: dict[str, str] = {}
for k, v in pa_columns_types.items():
if v is None:
athena_columns_types[k] = casts[k].replace(" ", "")
else:
try:
athena_columns_types[k] = pyarrow2athena(dtype=v)
except exceptions.UndetectedType as ex:
raise exceptions.UndetectedType(
"Impossible to infer the equivalent Athena data type "
f"for the {k} column. "
"It is completely empty (only null values) "
f"and has a too generic data type ({df[k].dtype}). "
"Please, cast this columns with a more deterministic data type "
f"(e.g. df['{k}'] = df['{k}'].astype('string')) or "
"pass the column schema as argument"
f"(e.g. dtype={{'{k}': 'string'}}"
) from ex
except exceptions.UnsupportedType as ex:
raise exceptions.UnsupportedType(f"Unsupported Pyarrow type: {v} for column {k}") from ex
_logger.debug("athena_columns_types: %s", athena_columns_types)
return athena_columns_types- 내부적으로 pyarrow_types_from_pandas() → pyarrow2athena() 순서로 호출됨
실제 컬럼별로 어떤 Pandas 타입이 Athena에서는 어떤 타입으로 저장되는지 매핑표
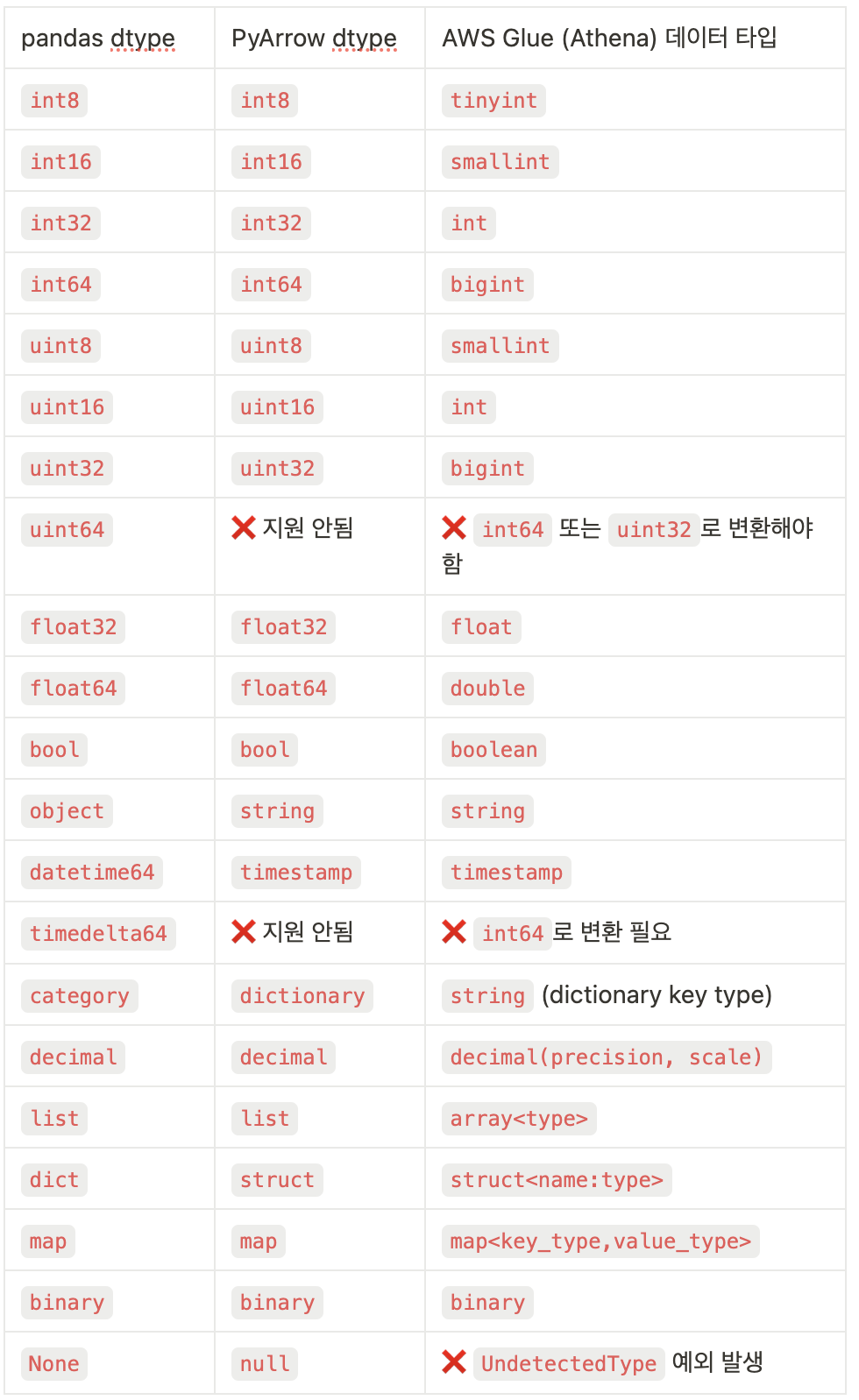
알게된 점 및 실무 팁
- Google Sheet에서 가져온 데이터는 항상 문자열(object)로 들어온다고 가정하자.
- Parquet 저장 전에는 df.astype()을 활용해 타입을 명시적으로 지정하거나, dtype={} 인자를 적극 활용하자.
- Glue 테이블 타입이 중요한 경우, 내부 로직을 이해하고 필요한 컬럼만 명시적으로 지정하는 전략도 유효하다.
- None만 존재하는 컬럼은 PyArrow가 타입을 추론하지 못해 예외(UndetectedType)를 발생시킬 수 있다.