
Amazon EMR의 대략적인 개념을 정리하기 위해 작성한 포스팅입니다. 잘못된 내용이 있으면 댓글로 남겨주시면 감사하겠습니다!
Overview of Amazon EMR - Amazon EMR
Overview of Amazon EMR This topic provides an overview of Amazon EMR clusters, including how to submit work to a cluster, how that data is processed, and the various states that the cluster goes through during processing. Understanding clusters and nodes T
docs.aws.amazon.com
What is Amazon EMR?
Amazon EMR은 빅데이터 프레임워크(예: Apache Hadoop 및 Apache Spark)를 AWS에서 운영하여 대량의 데이터를 처리하고 분석할 수 있도록 도와주는 관리형 클러스터 플랫폼이다. 이를 사용하여 분석 목적 및 비즈니스 인텔리전스 작업을 위한 데이터를 처리할 수 있으며 Amazon EMR은 Amazon S3 및 Amazon DynamoDB와 같은 다른 AWS 데이터 저장소와 데이터베이스로 대량의 데이터를 변환하고 이동시키는 기능을 제공한다.
Cluster와 Node
아마존 EMR의 핵심 구성요소는 클러스터이다. 클러스터는 Amazon EC2 인스턴스의 집합이다. (EC2는 가상 컴퓨팅 서비스)
클러스터 내 각 인스턴스를 노드라고하며, 각 노드는 클러스터 내에서 특정 역할을 수행하는 노드 유형(Node Type)을 갖는다.
AWS EMR은 각 노드 유형에 다양한 소프트웨어 구성 요소를 설치해, 각 노드가 Apache Hadoop과 같은 분산 애플리케이션 역할을 수행하게 한다.

1. 프라이머리 노드(Primary/Master node): 클러스터를 관리하고, 서로 다른 노드 간 데이터 및 작업의 분배를 조정하는 노드이다. 프라이머리 노드는 작업의 상태를 추적하고 클러스터들의 상태를 모니터링한다. 모든 클러스터에는 일반적으로 하나의 프라이머리 노드가 있으며, 프라이머리 노드만으로 구성된 단일 노드 클러스터를 만들 수도 있다. (Hadoop의 Namenode와 유사하다.)
2. 코어 노드(Core node): 클러스터의 하둡 분산 파일 시스템(HDFS)에 데이터를 저장하고 작업을 실행하는 노드이다. 멀티 노드 클러스터에는 적어도 하나의 코어 노드가 있다.
3. 태스크 노드(Task node): 작업만 실행하고 HDFS에 데이터를 저장하지 않는 노드이다. (optional)
Cluster에 작업 submit하기
AWS EMR에서 클러스터를 운영할 때, 작업을 지정하는 몇 가지 방법이 있다.
1. 클러스터 생성 시 단계로 작업 정의 제공: 클러스터 생성 시 단계(Step)를 정의하여 전체 작업을 지정할 수 있다. 이 방법은 주로 정해진 양의 데이터를 처리하고 데이터 처리가 완료되면 클러스터가 종료되는 경우에 사용된다. (데이터 변환 작업이나 배치 분석 등을 수행 후 클러스터를 종료하려는 경우에 적합하다.)
2. 장기 실행 클러스터 사용 및 단계 제출: 클러스터를 장기간 실행 상태로 유지하고, 필요할 때마다 Amazon EMR 콘솔, Amazon EMR API, 또는 AWS CLI를 사용하여 작업을 클러스터에 제출할 수 있다. 이 방법은 지속적으로 다양한 작업을 클러스터에 추가해야 할 때 유용하다. (여러 데이터 처리 작업을 순차적으로 또는 동시에 수행하려는 경우에 적합하다.)
3. 클러스터에 연결하여 작업 제출: 클러스터를 생성한 후, SSH를 통해 프라이머리 노드나 필요한 다른 노드에 연결할 수 있다. 연결된 후에는 설치된 애플리케이션의 인터페이스를 사용하여 스크립트를 실행하거나 대화형으로 쿼리를 제출하고 작업을 수행할 수 있다. (복잡한 데이터 분석이나 개발 작업을 클러스터에서 직접 관리하고 싶을 때 적합하다.)
데이터 처리
클러스터를 실행할 때 데이터 처리에 필요한 프레임워크와 애플리케이션을 선택하여 설치한다. Amazon EMR 클러스터에서 데이터를 처리하기 위해 설치된 애플리케이션(ex. Spark, Hadoop 등)에 직접 작업(job)이나 쿼리를 제출할 수 있으며, 클러스터에서 단계(step)를 실행할 수도 있다.
애플리케이션에 직접 작업 제출하기
Amazon EMR 클러스터에 설치된 소프트웨어와 직접 상호 작용하며 작업을 제출할 수 있다. 이를 위해 일반적으로 보안 연결을 통해 프라이머리 노드에 연결하고, 클러스터에서 직접 실행되는 소프트웨어의 인터페이스와 도구에 접근한다.
데이터를 처리하기 위한 단계 수행하기
각 단계(Step)는 클러스터에서 수행되어야 할 작업의 단위이다.
1. 처리 시작 요청: 데이터 처리를 시작하기 위한 요청이 제출된다.
2. 단계 상태 설정: 모든 단계의 상태가 ’PENDING(대기 중)’으로 설정된다.
3. 첫 번째 단계 실행: 시퀀스의 첫 번째 단계가 시작되면 해당 단계의 상태가 ’RUNNING(실행 중)’으로 변경된다. 다른 단계들은 ‘PENDING’ 상태를 유지한다.
4. 단계 완료: 첫 번째 단계가 완료되면 상태가 ’COMPLETED(완료됨)’로 변경된다.
5. 다음 단계 실행: 시퀀스의 다음 단계가 시작되고, 그 상태가 ‘RUNNING’으로 변경된다. 이 단계가 완료되면 상태가 ‘COMPLETED’로 변경된다.
6. 반복 실행: 이 패턴은 모든 단계가 완료될 때까지 반복되며, 모든 처리가 끝나면 종료된다.

입력 데이터는 Amazon S3 또는 HDFS와 같은 파일 시스템에서 시작해, 각 단계를 거치면서 처리되고, 최종적으로 지정된 위치(예: Amazon S3 버킷)에 출력 데이터를 쓰게 된다.

Amazon EMR 클러스터에서 데이터를 처리하는 동안 특정 단계가 실패하면 해당 단계는 ’FAILED(실패)’로 변경된다. 이후의 단계들은 기본 설정에 따라 앞선 단계의 실패로 인해 ‘CANCELLED(취소됨)’ 상태가 되어 실행되지 않는다. 하지만, 사용자는 이 기본 동작을 변경하여 실패한 단계를 무시하고 나머지 단계들이 계속 진행되도록 설정할 수 있으며, 클러스터를 즉시 종료하는 옵션도 선택할 수 있다.
클러스터 라이프 사이클 이해
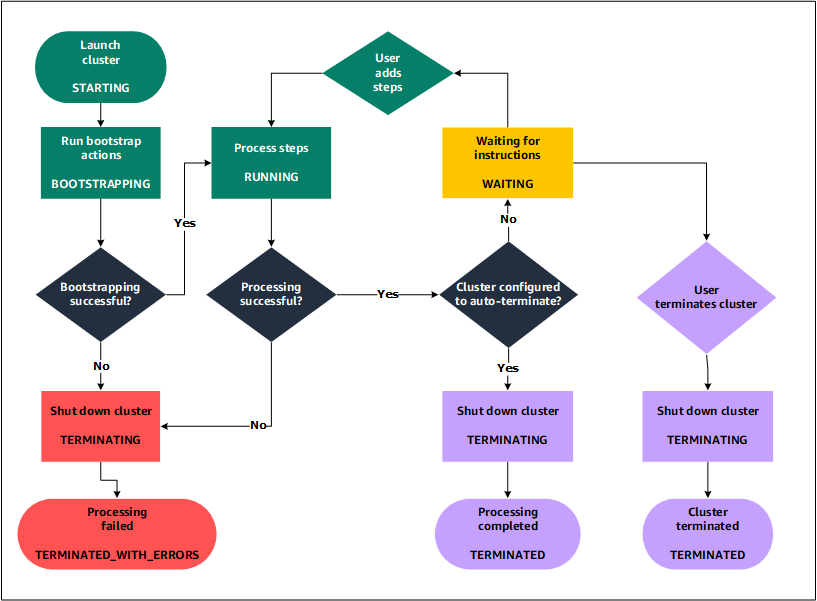
1. EC2 인스턴스 프로비저닝: Amazon EMR은 사용자의 사양에 따라 각 인스턴스를 클러스터에 프로비저닝한다. 이때 Amazon EMR의 기본 AMI 또는 사용자가 지정한 커스텀 Amazon Linux AMI를 사용한다. 이 단계에서 클러스터 상태는 ’STARTING(시작 중)’이다.
- 프로비저닝은 필요한 컴퓨팅 자원을 설정하고 사용할 준비를 하는 과정이다. 예를 들어, 클라우드 환경에서 가상 서버, 스토리지, 네트워크 등을 설정하고 할당하는 것이 포함된다. 즉, 사용자의 요구에 맞게 자원을 준비하고 구성하는 단계이다.
2. 부트스트랩 작업 실행: 각 인스턴스에서 사용자가 지정한 부트스트랩 작업을 실행한다. 이 작업을 통해 커스텀 애플리케이션 설치 및 필요한 맞춤 설정을 할 수 있다. 이 단계에서 클러스터 상태는 ’BOOTSTRAPPING(부트스트래핑 중)’이다.
- 부트스트랩은 시스템이 시작될 때 자동으로 실행되는 작업들을 말한다. 특히 서버나 클라우드 서비스에서는 이 과정을 통해 추가적인 소프트웨어 설치나 설정 변경 등을 자동으로 수행한다. 예를 들어, 서버가 처음 시작할 때 필요한 프로그램을 설치하거나 설정을 조정하는 스크립트를 실행하는 것이 부트스트랩 작업에 해당한다.
3. 네이티브 애플리케이션 설치: 클러스터 생성 시 지정한 네이티브 애플리케이션(예: Hive, Hadoop, Spark 등)을 설치한다.
4. 클러스터 상태 RUNNING: 부트스트랩 작업이 성공적으로 완료되고 네이티브 애플리케이션 설치가 끝나면, 클러스터 상태는 ’RUNNING(실행 중)’이 된다. 이 시점에서 클러스터 인스턴스에 연결할 수 있으며, 클러스터는 생성 시 지정한 단계를 순차적으로 실행한다.
5. WAITING 상태: 모든 단계가 성공적으로 실행되면, 클러스터는 ‘WAITING(대기 중)’ 상태로 전환된다. 클러스터가 마지막 단계 완료 후 자동 종료로 설정된 경우 ‘TERMINATING(종료 중)’ 상태로 전환되고 그 후 ‘TERMINATED(종료됨)’ 상태가 된다. 클러스터를 대기 상태로 설정한 경우, 더 이상 필요하지 않을 때 수동으로 종료해야 한다. 수동 종료 후 클러스터는 ‘TERMINATING’ 상태로 전환되고, 이후 ‘TERMINATED’ 상태가 됩니다.
6. 실패와 종료 보호: 클러스터 라이프사이클 동안 실패가 발생하면 종료 보호를 활성화하지 않은 경우 Amazon EMR은 클러스터와 모든 인스턴스를 종료한다. 실패로 인해 클러스터가 종료되면 클러스터에 저장된 모든 데이터가 삭제되고, 클러스터 상태는 ’TERMINATED_WITH_ERRORS(오류와 함께 종료됨)’로 설정된다.
AWS EMR 장단점
더 많은 장점은 이 페이지에서 확인할 수 있다.
장점
1. 확장성 및 유연성: 사용자는 데이터 처리 요구에 맞춰 클러스터의 크기를 쉽게 조절할 수 있으며, 다양한 인스턴스 타입과 결합하여 사용할 수 있다.
2. 비용 효율성: 온디맨드, 리저브드, 스팟 인스턴스 등 다양한 가격 모델을 제공해 비용을 절감이 가능하다.
3. 통합 및 호환성: 다른 AWS 서비스와의 우수한 통합을 제공하여, 데이터 관리와 분석 작업을 원활하게 수행할 수 있다.
단점
1. 비용 관리의 어려움: EMR의 사용이 증가함에 따라 예상치 못한 높은 비용이 발생할 수 있다.
- 데이터 전송 비용: AWS EMR을 사용하면 데이터를 EMR 클러스터와 다른 AWS 서비스(예: Amazon S3) 간에 자주 이동할 수 있다. 이 데이터 이동에는 비용이 발생하며, 특히 데이터 양이 많을 경우 상당한 비용이 청구될 수 있다.
2. 복잡한 설정과 관리: 클러스터 설정, 소프트웨어 관리, 성능 최적화 등이 복잡할 수 있다.
3. 보안 설정 복잡성: 강력한 보안 기능을 제공하지만, 이를 올바르게 구성하지 않으면 데이터 유출과 같은 보안 문제가 발생할 수 있다 .
'Cloud > AWS' 카테고리의 다른 글
| Amazon EMR architecture Overview (0) | 2024.09.09 |
|---|---|
| AWSome Day 정리 (0) | 2024.07.19 |
| AWS VPC (0) | 2024.06.09 |
| AWS EC2 기초 (0) | 2024.06.01 |
| AWS IAM(Identity and Access Mangement) (0) | 2024.05.31 |