
데이터 엔지니어 관점에서 '데이터 중심 애플리케이션 설계'를 위해 해당 책을 읽고, 여러 직군의 사람들과 스터디를 진행하게 됐습니다.
책의 전체 내용을 단순히 나열식으로 정리하기보다는 아래의 방식으로 책을 정리해보려고 합니다.
잘못된 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
데이터 중심 애플리케이션 설계 | 마틴 클레프만 - 교보문고
데이터 중심 애플리케이션 설계 | 데이터는 오늘날 시스템을 설계할 때 마주치는 많은 도전 과제 중에서도 가장 중심에 있다. 확장성, 일관성, 신뢰성, 효율성, 유지보수성과 같은 해결하기 어려
product.kyobobook.co.kr
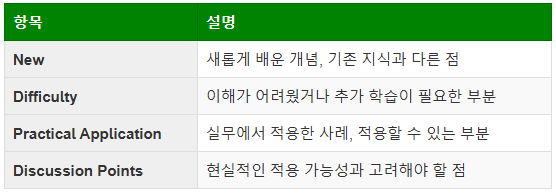
1. 새롭게 배운 개념(New)
🔹 데이터 시스템이란?
📌 데이터 시스템(Data System)은 데이터를 저장하고, 처리하고, 전송하는 데 사용되는 다양한 기술과 도구들의 조합을 의미한다.
- 기존에는 데이터베이스(DB), 메시지 큐(Message Queue), 캐시(Cache) 등 각각 따로 분류됐었다.
- 최근에는 이러한 경계가 모호해지고, 여러 기능이 결합된 형태의 도구들이 등장하면서 "데이터 시스템"이라는 포괄적인 용어가 필요해졌다.
🔹 왜 ‘데이터 시스템’이라는 용어를 사용해야 할까?
- 전통적인 분류로 설명하기 어려운 도구들이 많아졌기 때문!
- Redis: 원래는 캐시(Cache)로 쓰였지만, 영구 저장 기능도 있어서 데이터스토어 역할도 가능함
- Apache Kafka: 메시지 큐(Message Queue)로 시작했지만, 지속성을 보장해서 데이터베이스처럼 활용 가능함
→ 즉, 예전처럼 "이건 DB야, 이건 메시지 큐야"라고 단순히 나눌 수 없게 됐다.
- 하나의 도구만으로 데이터 저장 & 처리를 해결할 수 없는 경우가 많아졌기 때문!
- 과거에는 하나의 관계형 데이터베이스(RDBMS)로 모든 걸 처리했지만,
- 요즘에는 데이터 캐싱, 검색 최적화, 비동기 메시징 같은 다양한 요구사항을 충족해야 함
- 각 기능에 맞는 도구를 조합해서 하나의 데이터 시스템을 구성하는 방식이 일반적인 방식이 됨
🔹 부하 매개변수 (Load Parameters)
- 부하(load)는 단순히 "트래픽이 많다"라고 말하는 것이 아니라, 몇 개의 숫자로 표현할 수 있음
- 시스템마다 가장 적절한 부하 매개변수가 다름
- 예시
- 웹 서버 → 초당 요청 수(QPS, Queries Per Second)
- 데이터베이스 → 읽기 대 쓰기 비율(Read-to-Write Ratio)
- 대화방 서비스 → 동시 활성 사용자 수(Concurrent Users)
- 캐시 → 캐시 적중률(Cache Hit Rate)
- 예시
- 평균적인 부하보다 소수의 극단적인 경우(예: 특정 사용자의 트윗이 너무 많은 팔로워에게 전달됨)가 시스템 병목을 초래할 수도 있음
2. 어려웠던 개념(Difficulty) + 추가 학습이 필요한 부분
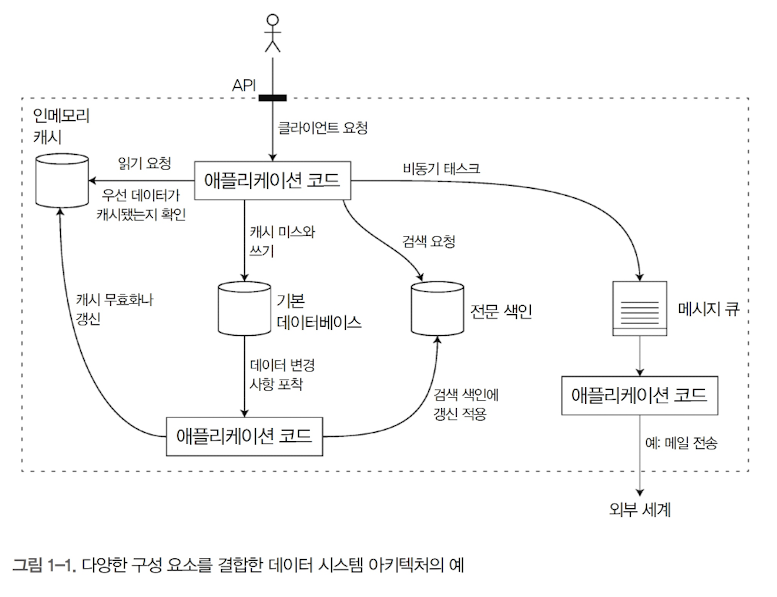
🔹 데이터 시스템 아키텍처의 예
인메모리 캐시 (예: Redis, Memcached)
- 사용자가 API를 호출하면, 애플리케이션은 먼저 캐시에서 데이터를 찾음
- 왜? 캐시는 빠르게 데이터를 제공할 수 있어서 DB 부하를 줄이고 성능을 높임
- 만약 캐시에 데이터가 없다면? → 데이터베이스에서 조회한 후, 캐시에 저장
기본 데이터베이스 (예: MySQL, PostgreSQL, MongoDB)
- 데이터의 최종 저장소 역할을 하는 곳.
- 캐시에서 데이터를 찾지 못한 경우, 여기에서 데이터를 가져옴
- 데이터가 변경되면, 변경 사항을 감지하여 검색 인덱스와 캐시를 업데이트해야 함
전문 검색 엔진 (예: Elasticsearch, Solr)
- 사용자가 검색 요청을 하면, 애플리케이션은 기본 데이터베이스 대신 검색 엔진을 활용함
- 왜? 일반 데이터베이스는 검색 속도가 느릴 수 있지만, 검색 엔진은 빠른 검색 최적화 기능을 제공하기 때문
메시지 큐 (예: Kafka, RabbitMQ)
- 이메일 전송과 같은 비동기 작업을 처리하는 역할
- 왜? 모든 요청을 동기적으로 처리하면 성능이 떨어지므로, 별도의 메시지 큐에서 비동기적으로 실행하게 함
- 예를 들어, 주문이 완료되면 즉시 응답을 보내고, 이메일 전송 작업은 메시지 큐에서 나중에 처리하는 방식
🔹 꼬리 지연 시간 (Tail Latency) & 상위 백분위 응답 시간
- 꼬리 지연 시간(Tail Latency) = 전체 응답 시간 중 가장 느린 요청들의 지연 시간
- 시스템의 평균 응답 시간이 빠르더라도, 일부 요청(특히 상위 백분위, P99, P99.9)은 매우 느릴 수 있음
- 📌 왜 중요할까?
- 99.9백분위(P99.9) = 1000개의 요청 중 가장 느린 1개 요청을 의미
- 아마존 같은 기업은 내부 시스템의 응답 시간을 99.9백분위 기준으로 보장
- 이유? VIP 고객(많이 구매하는 고객)일수록 데이터가 많고, 더 느린 응답을 경험할 가능성이 큼
3. 실무 적용 사례(Practical Application)
🔹 팬 아웃(Fan-out)이란?
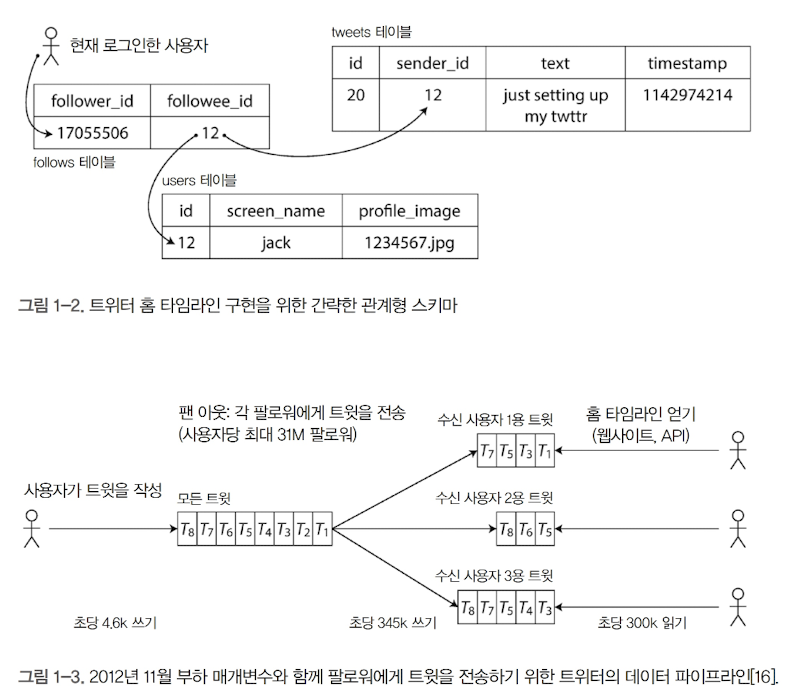
📌 "한 개의 입력이 여러 개의 출력으로 전파되는 현상" (ex. 트위터에서의 팬 아웃)
- 즉, 하나의 이벤트가 여러 대상에게 전달되는 구조
- 주로 SNS, 메시징 시스템, 로그 전송 시스템 등에서 발생함
예제: 트위터에서의 확장성 문제: 팬 아웃
- 사용자가 트윗을 작성하면, 해당 트윗이 모든 팔로워의 홈 타임라인에 반영됨
- 사용자가 1만 명의 팔로워를 가지고 있다면, 트윗 1개가 1만 개의 홈 타임라인에 삽입됨
- 즉, 1개의 입력(트윗)이 N개의 출력(팔로워들에게 전파)으로 확장되는 구조 = 팬 아웃
- 어떤 사용자는 수천만 명의 팔로워를 가질 수 있음
- 즉, 트윗 하나를 올릴 때마다 수천만 개의 홈 타임라인에 반영해야 하는 문제가 발생
4. 토론할 거리(Discussion Points)
🔹 데이터 시스템의 확장성과 정합성의 트레이드오프
✔ 확장성과 정합성을 모두 만족하는 시스템 설계가 가능한가?
- Redis 캐시를 활용하면 읽기 속도를 높일 수 있지만, 데이터 정합성 문제가 발생할 수 있음
- NoSQL을 사용하면 확장성은 확보되지만 ACID 트랜잭션을 포기해야 하는 경우가 많음
- 결국 CAP 이론을 고려하여 어떤 선택이 더 적절한가?
✔ 트위터의 팬 아웃 문제를 일반적인 데이터 시스템에 적용하면 어떨까?
- SNS와 같은 대규모 팬 아웃 시스템이 아닌 데이터 분석 시스템에서도 팬 아웃 패턴이 필요할 수 있음
- 예를 들어 하나의 이벤트가 여러 애널리틱스 시스템으로 전파될 때 Kafka를 활용하는 것이 효과적인가?
🔹 꼬리 지연(Tail Latency) 관리 전략의 실무 적용 가능성
✔ 꼬리 지연을 줄이기 위해 어떤 기술을 적용할 수 있는가?
- 데이터 시스템에서 가장 느린 요청이 전체 성능을 저하시키지 않도록 비동기 처리 전략(예: 우선순위 큐 적용, 캐싱, 로드 밸런싱)을 고려 필요
- 클라우드 환경에서 서버리스(Serverless) 구조를 활용하면 꼬리 지연 문제를 해결할 수 있을까?
✔ 성능을 위해 비동기 처리를 증가시키면, 결국 사용자 경험이 나빠지지 않을까?
- 비동기 처리 방식은 일반적으로 성능을 개선하지만, 사용자가 즉각적인 응답을 원할 때는 UX를 해칠 수 있음
- 트위터는 쓰기 시점을 희생하여 읽기 성능을 높였지만, 다른 애플리케이션에서는 반대 전략이 필요할 수도 있음
'Data Engineering > Data' 카테고리의 다른 글
| Garbage In, Garbage Out! 당신의 데이터 믿을만한가요? (0) | 2024.11.10 |
|---|---|
| [빅데이터를 지탱하는 기술] 2. 빅데이터의 탐색 (0) | 2024.09.07 |
| [빅데이터를 지탱하는 기술] 1. 빅데이터의 기초 지식 (0) | 2024.08.15 |
데이터 엔지니어 관점에서 '데이터 중심 애플리케이션 설계'를 위해 해당 책을 읽고, 여러 직군의 사람들과 스터디를 진행하게 됐습니다.
책의 전체 내용을 단순히 나열식으로 정리하기보다는 아래의 방식으로 책을 정리해보려고 합니다.
잘못된 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
데이터 중심 애플리케이션 설계 | 마틴 클레프만 - 교보문고
데이터 중심 애플리케이션 설계 | 데이터는 오늘날 시스템을 설계할 때 마주치는 많은 도전 과제 중에서도 가장 중심에 있다. 확장성, 일관성, 신뢰성, 효율성, 유지보수성과 같은 해결하기 어려
product.kyobobook.co.kr
1. 새롭게 배운 개념(New)
🔹 데이터 시스템이란?
📌 데이터 시스템(Data System)은 데이터를 저장하고, 처리하고, 전송하는 데 사용되는 다양한 기술과 도구들의 조합을 의미한다.
- 기존에는 데이터베이스(DB), 메시지 큐(Message Queue), 캐시(Cache) 등 각각 따로 분류됐었다.
- 최근에는 이러한 경계가 모호해지고, 여러 기능이 결합된 형태의 도구들이 등장하면서 "데이터 시스템"이라는 포괄적인 용어가 필요해졌다.
🔹 왜 ‘데이터 시스템’이라는 용어를 사용해야 할까?
- 전통적인 분류로 설명하기 어려운 도구들이 많아졌기 때문!
- Redis: 원래는 캐시(Cache)로 쓰였지만, 영구 저장 기능도 있어서 데이터스토어 역할도 가능함
- Apache Kafka: 메시지 큐(Message Queue)로 시작했지만, 지속성을 보장해서 데이터베이스처럼 활용 가능함
→ 즉, 예전처럼 "이건 DB야, 이건 메시지 큐야"라고 단순히 나눌 수 없게 됐다.
- 하나의 도구만으로 데이터 저장 & 처리를 해결할 수 없는 경우가 많아졌기 때문!
- 과거에는 하나의 관계형 데이터베이스(RDBMS)로 모든 걸 처리했지만,
- 요즘에는 데이터 캐싱, 검색 최적화, 비동기 메시징 같은 다양한 요구사항을 충족해야 함
- 각 기능에 맞는 도구를 조합해서 하나의 데이터 시스템을 구성하는 방식이 일반적인 방식이 됨
🔹 부하 매개변수 (Load Parameters)
- 부하(load)는 단순히 "트래픽이 많다"라고 말하는 것이 아니라, 몇 개의 숫자로 표현할 수 있음
- 시스템마다 가장 적절한 부하 매개변수가 다름
- 예시
- 웹 서버 → 초당 요청 수(QPS, Queries Per Second)
- 데이터베이스 → 읽기 대 쓰기 비율(Read-to-Write Ratio)
- 대화방 서비스 → 동시 활성 사용자 수(Concurrent Users)
- 캐시 → 캐시 적중률(Cache Hit Rate)
- 예시
- 평균적인 부하보다 소수의 극단적인 경우(예: 특정 사용자의 트윗이 너무 많은 팔로워에게 전달됨)가 시스템 병목을 초래할 수도 있음
2. 어려웠던 개념(Difficulty) + 추가 학습이 필요한 부분
🔹 데이터 시스템 아키텍처의 예
인메모리 캐시 (예: Redis, Memcached)
- 사용자가 API를 호출하면, 애플리케이션은 먼저 캐시에서 데이터를 찾음
- 왜? 캐시는 빠르게 데이터를 제공할 수 있어서 DB 부하를 줄이고 성능을 높임
- 만약 캐시에 데이터가 없다면? → 데이터베이스에서 조회한 후, 캐시에 저장
기본 데이터베이스 (예: MySQL, PostgreSQL, MongoDB)
- 데이터의 최종 저장소 역할을 하는 곳.
- 캐시에서 데이터를 찾지 못한 경우, 여기에서 데이터를 가져옴
- 데이터가 변경되면, 변경 사항을 감지하여 검색 인덱스와 캐시를 업데이트해야 함
전문 검색 엔진 (예: Elasticsearch, Solr)
- 사용자가 검색 요청을 하면, 애플리케이션은 기본 데이터베이스 대신 검색 엔진을 활용함
- 왜? 일반 데이터베이스는 검색 속도가 느릴 수 있지만, 검색 엔진은 빠른 검색 최적화 기능을 제공하기 때문
메시지 큐 (예: Kafka, RabbitMQ)
- 이메일 전송과 같은 비동기 작업을 처리하는 역할
- 왜? 모든 요청을 동기적으로 처리하면 성능이 떨어지므로, 별도의 메시지 큐에서 비동기적으로 실행하게 함
- 예를 들어, 주문이 완료되면 즉시 응답을 보내고, 이메일 전송 작업은 메시지 큐에서 나중에 처리하는 방식
🔹 꼬리 지연 시간 (Tail Latency) & 상위 백분위 응답 시간
- 꼬리 지연 시간(Tail Latency) = 전체 응답 시간 중 가장 느린 요청들의 지연 시간
- 시스템의 평균 응답 시간이 빠르더라도, 일부 요청(특히 상위 백분위, P99, P99.9)은 매우 느릴 수 있음
- 📌 왜 중요할까?
- 99.9백분위(P99.9) = 1000개의 요청 중 가장 느린 1개 요청을 의미
- 아마존 같은 기업은 내부 시스템의 응답 시간을 99.9백분위 기준으로 보장
- 이유? VIP 고객(많이 구매하는 고객)일수록 데이터가 많고, 더 느린 응답을 경험할 가능성이 큼
3. 실무 적용 사례(Practical Application)
🔹 팬 아웃(Fan-out)이란?
📌 "한 개의 입력이 여러 개의 출력으로 전파되는 현상" (ex. 트위터에서의 팬 아웃)
- 즉, 하나의 이벤트가 여러 대상에게 전달되는 구조
- 주로 SNS, 메시징 시스템, 로그 전송 시스템 등에서 발생함
예제: 트위터에서의 확장성 문제: 팬 아웃
- 사용자가 트윗을 작성하면, 해당 트윗이 모든 팔로워의 홈 타임라인에 반영됨
- 사용자가 1만 명의 팔로워를 가지고 있다면, 트윗 1개가 1만 개의 홈 타임라인에 삽입됨
- 즉, 1개의 입력(트윗)이 N개의 출력(팔로워들에게 전파)으로 확장되는 구조 = 팬 아웃
- 어떤 사용자는 수천만 명의 팔로워를 가질 수 있음
- 즉, 트윗 하나를 올릴 때마다 수천만 개의 홈 타임라인에 반영해야 하는 문제가 발생
4. 토론할 거리(Discussion Points)
🔹 데이터 시스템의 확장성과 정합성의 트레이드오프
✔ 확장성과 정합성을 모두 만족하는 시스템 설계가 가능한가?
- Redis 캐시를 활용하면 읽기 속도를 높일 수 있지만, 데이터 정합성 문제가 발생할 수 있음
- NoSQL을 사용하면 확장성은 확보되지만 ACID 트랜잭션을 포기해야 하는 경우가 많음
- 결국 CAP 이론을 고려하여 어떤 선택이 더 적절한가?
✔ 트위터의 팬 아웃 문제를 일반적인 데이터 시스템에 적용하면 어떨까?
- SNS와 같은 대규모 팬 아웃 시스템이 아닌 데이터 분석 시스템에서도 팬 아웃 패턴이 필요할 수 있음
- 예를 들어 하나의 이벤트가 여러 애널리틱스 시스템으로 전파될 때 Kafka를 활용하는 것이 효과적인가?
🔹 꼬리 지연(Tail Latency) 관리 전략의 실무 적용 가능성
✔ 꼬리 지연을 줄이기 위해 어떤 기술을 적용할 수 있는가?
- 데이터 시스템에서 가장 느린 요청이 전체 성능을 저하시키지 않도록 비동기 처리 전략(예: 우선순위 큐 적용, 캐싱, 로드 밸런싱)을 고려 필요
- 클라우드 환경에서 서버리스(Serverless) 구조를 활용하면 꼬리 지연 문제를 해결할 수 있을까?
✔ 성능을 위해 비동기 처리를 증가시키면, 결국 사용자 경험이 나빠지지 않을까?
- 비동기 처리 방식은 일반적으로 성능을 개선하지만, 사용자가 즉각적인 응답을 원할 때는 UX를 해칠 수 있음
- 트위터는 쓰기 시점을 희생하여 읽기 성능을 높였지만, 다른 애플리케이션에서는 반대 전략이 필요할 수도 있음
'Data Engineering > Data' 카테고리의 다른 글
| Garbage In, Garbage Out! 당신의 데이터 믿을만한가요? (0) | 2024.11.10 |
|---|---|
| [빅데이터를 지탱하는 기술] 2. 빅데이터의 탐색 (0) | 2024.09.07 |
| [빅데이터를 지탱하는 기술] 1. 빅데이터의 기초 지식 (0) | 2024.08.15 |